

Uber System Design
From the user’s perspective, Uber’s system design feels almost suspiciously simple.

From the user’s perspective, Uber’s system design feels almost suspiciously simple. You open an app, type a destination, watch a few cars move around on a map, and within minutes someone arrives to take you somewhere else. The interaction itself feels lightweight. There are no complicated workflows visible to the rider. No sense that the system is doing anything particularly extraordinary underneath the interface. The app appears to behave like a normal consumer product: request, response, confirmation. A car arrives. A payment processes. The interaction ends.
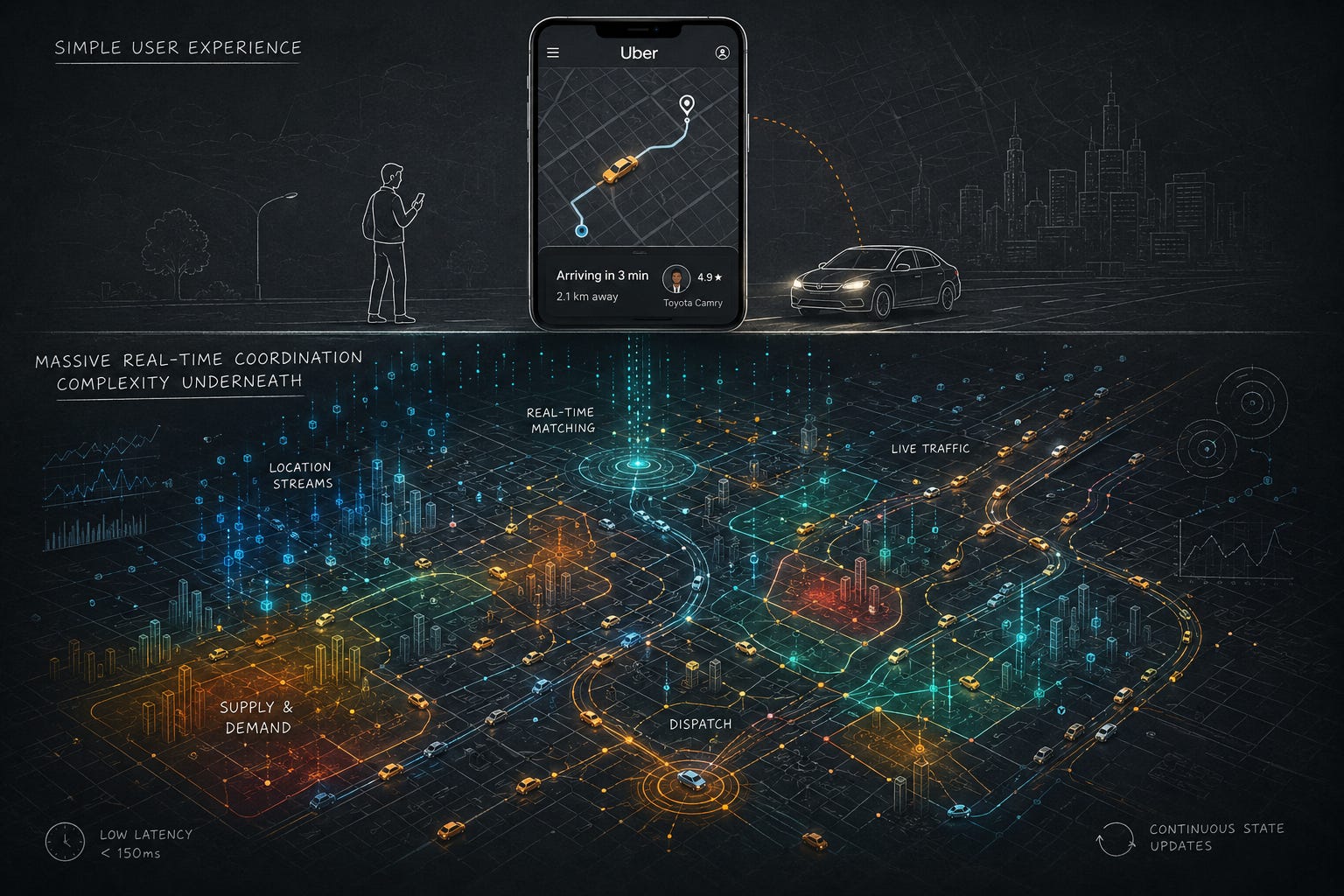
But systems like Uber are fascinating precisely because the simplicity users experience is operationally deceptive. Underneath that calm interface exists one of the most difficult categories of distributed systems ever built at consumer scale. Ride-sharing systems are not simply mobile applications connected to maps and payment APIs. They are real-time coordination environments operating inside continuously changing physical worlds. Drivers move constantly. Riders move constantly. Traffic conditions evolve minute by minute. Supply and demand fluctuate unpredictably across geography and time. The system is not merely serving information. It is coordinating movement itself.
The hardest systems are often the ones users barely notice while they’re working.
This is what makes Uber architecturally interesting in ways that traditional web applications often are not. Most software systems operate inside relatively stable digital environments. Ride-sharing systems operate inside unpredictable physical reality. They must continuously observe, interpret, and react to events happening across cities in real time while maintaining low latency, operational reliability, and user trust simultaneously. The complexity is not only computational. It is environmental. And environmental complexity behaves very differently from ordinary application complexity.
Why Uber is not “just another app”
It is tempting to think about Uber as another large-scale consumer application similar to social networks, e-commerce platforms, or traditional SaaS products. But mobility systems behave differently because they exist inside time-sensitive, geographically distributed environments where delayed coordination immediately affects physical outcomes. A social media feed can tolerate occasional latency spikes. A ride-sharing system cannot tolerate uncertainty the same way because users are waiting in parking lots, airports, sidewalks, and unfamiliar neighborhoods expecting physical movement to happen predictably.
Traditional web applications mostly manage digital state. Ride-sharing systems manage continuously evolving real-world coordination. That distinction changes architectural priorities significantly. Every interaction becomes time-sensitive. Every delay influences trust. Every inaccurate ETA affects human behavior directly. The system must not only process requests correctly, but process them quickly enough that coordination remains operationally meaningful in the real world.
This creates a very different type of infrastructure problem. Uber-like systems must reason about dynamic geography, moving entities, fluctuating traffic conditions, localized demand spikes, and constantly changing system state. The architecture behaves less like a traditional request-response application and more like a continuously adapting coordination engine. The software is not simply serving users. It is orchestrating movement across cities.
And importantly, the system is coordinating humans, which makes predictability dramatically harder. Human systems rarely behave as cleanly as infrastructure diagrams suggest.
The problem of real-time coordination
At the center of Uber’s architecture is a deceptively difficult coordination problem: matching riders and drivers continuously under changing constraints. On paper, this sounds relatively manageable. A rider requests a ride. Nearby drivers are identified. A match occurs. But operationally, the problem expands immediately because none of the underlying conditions remain stable for very long.
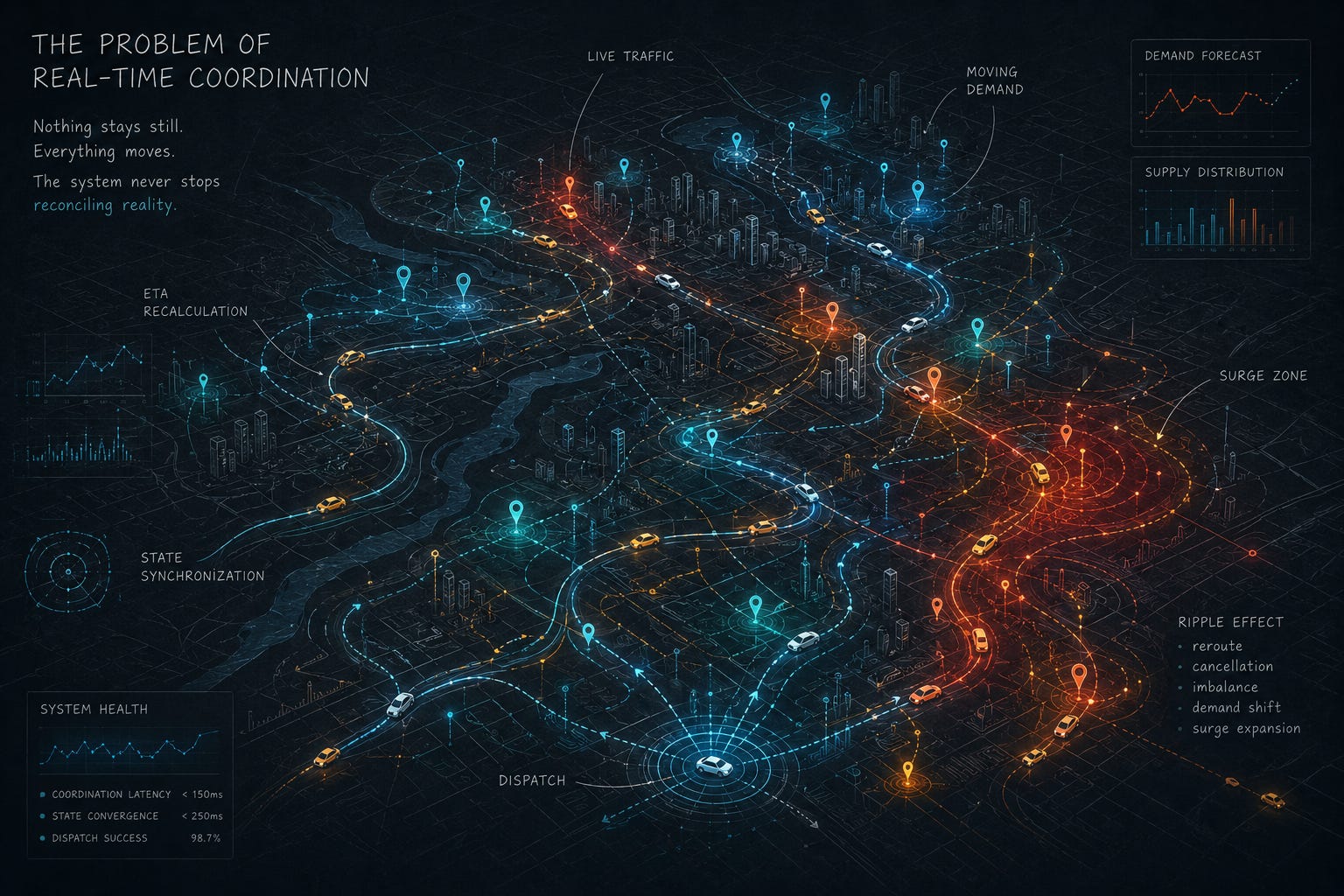
Drivers move constantly between regions. Riders may change pickup locations while waiting. Traffic conditions alter route efficiency unpredictably. Local demand spikes appear suddenly after concerts, sporting events, weather changes, or transit failures. The system must continuously recalculate positioning, availability, estimated arrival times, and pricing while coordinating millions of concurrent state transitions simultaneously.
Drivers are moving
Riders are moving
Traffic changes constantly
Demand changes minute by minute
This means the system cannot rely heavily on static assumptions. Most distributed systems reason about relatively stable infrastructure state. Mobility systems reason about continuously changing environmental state. Coordination itself becomes the core systems challenge. The architecture must optimize not only for correctness, but for responsiveness under uncertainty.
What makes this especially difficult is that coordination delays propagate behaviorally. A slightly delayed match may cause a driver to accept another ride. A poor ETA prediction may trigger a cancellation. A surge pricing delay may distort supply incentives across an entire region. Small timing issues influence larger system behavior because the participants themselves adapt dynamically in response to the platform.
The system therefore behaves less like software executing workflows and more like an ecosystem reacting continuously to itself.
Geospatial systems quietly become infrastructure
One of the less obvious realities of mobility platforms is that geography itself becomes a foundational infrastructure concern. Location is not simply metadata attached to requests. It shapes partitioning strategies, routing decisions, matching behavior, regional scaling models, and operational coordination across the entire architecture.
Geospatial indexing becomes critical because the system must identify nearby drivers quickly across continuously changing regions. Proximity search operates under extremely tight latency constraints because matching speed directly influences user perception. Region partitioning becomes operationally important because cities behave differently from one another in terms of density, traffic patterns, infrastructure reliability, and rider behavior.
The interesting thing about geospatial systems is that they fundamentally distort how distributed systems scale. Traditional applications often scale relatively cleanly through horizontal partitioning because users interact primarily with logical data boundaries. Mobility systems scale geographically. The architecture must reason about neighborhoods, traffic corridors, airports, event venues, and regional demand concentration dynamically.
This also creates unusual operational edge cases. Dense urban centers behave differently from suburban regions. Airports behave differently from residential zones. Weather events alter mobility patterns unpredictably. A globally distributed ride-sharing system is therefore not one system operating uniformly everywhere. It is thousands of localized coordination environments operating simultaneously under different physical conditions.
The infrastructure must adapt continuously to geography because geography itself shapes system behavior operationally.
Event-driven systems and constant state changes
Uber-like systems naturally evolve toward event-driven architectures because the environment itself behaves as a stream of continuously changing events. Ride requests, cancellations, location updates, payment confirmations, driver availability changes, route recalculations, traffic updates, and pricing adjustments all occur asynchronously across the platform simultaneously.
This creates architectures where the system state is never fully static. Traditional web applications often process relatively isolated transactions. Mobility systems process ongoing streams of environmental change. Every interaction potentially triggers downstream reactions across multiple services, queues, matching engines, pricing systems, and notification pipelines.
Systems like Uber don’t process isolated requests. They process continuously evolving reality.
The operational consequence is that the architecture becomes highly coordination-dependent. Event ordering matters. Timing matters. State synchronization matters. Delayed propagation of events can produce inconsistencies that immediately affect users operationally. A delayed driver status update may trigger incorrect ride assignments. A lagging pricing event may distort market balancing behavior across regions.
Event-driven architectures work well here because they allow systems to react asynchronously to evolving conditions without centralizing every workflow inside monolithic request chains. But they also make debugging substantially harder. Failures emerge across distributed event propagation paths rather than explicit synchronous transactions. Understanding system behavior requires reconstructing flows across streams of asynchronous state transitions occurring in parallel.
And as event volume increases, maintaining operational visibility becomes increasingly difficult.
Latency becomes a user experience problem immediately
Most large-scale systems care about latency eventually. Ride-sharing systems care about latency immediately. Matching delays affect rider trust. Slow ETA updates affect confidence. Delayed route recalculations frustrate drivers. Surge pricing lag creates market imbalance. In mobility systems, latency is not simply an infrastructure metric. It becomes part of the product experience directly.
This changes architectural priorities significantly. Milliseconds matter because human perception responds strongly to uncertainty in coordination systems. Users may tolerate slower page loads on social platforms occasionally. They tolerate uncertainty much less gracefully when waiting for transportation in real-world environments.
The challenge is that mobility systems generate latency-sensitive workloads across multiple infrastructure layers simultaneously. Matching engines require low-latency proximity calculations. ETA systems continuously process mapping and traffic information. Location updates propagate constantly across networks. Pricing systems react dynamically to fluctuating demand conditions.
And unlike many distributed systems, these workloads interact tightly with human behavior. A delay changes user decisions. A poor estimate alters cancellation patterns. Latency therefore affects not only infrastructure efficiency, but also ecosystem stability itself.
This creates architectures heavily optimized around responsiveness because responsiveness directly shapes platform trust.
The difficulty of designing systems around humans
One of the reasons Uber-like systems are architecturally difficult is that humans behave unpredictably. Traditional infrastructure problems often assume relatively stable interaction patterns. Mobility platforms coordinate human decisions continuously, and human decisions rarely behave deterministically.
Riders cancel unexpectedly. Drivers reject rides strategically. Demand spikes emerge emotionally rather than mathematically. Surge pricing changes participant behavior instantly. Cultural differences alter platform usage patterns across cities and regions. Even weather affects coordination behavior in ways that infrastructure models must eventually account for operationally.
The system therefore operates inside a feedback loop where platform behavior influences user behavior, which then reshapes system behavior again. Surge pricing may attract more drivers while simultaneously reducing rider demand. Longer ETAs increase cancellations, which further distorts matching efficiency. Incentive systems reshape geographical positioning patterns dynamically.
What makes this especially difficult is that infrastructure decisions become behavioral decisions indirectly. Matching logic influences driver incentives. ETA accuracy influences trust. Pricing responsiveness influences market equilibrium. The architecture is not simply computational infrastructure anymore. It becomes behavioral infrastructure operating across large-scale human coordination systems.
And human systems are always more complicated than software systems alone.
Reliability becomes operationally emotional
Failures inside mobility systems feel unusually personal because they affect physical coordination directly. A delayed social feed post is mildly annoying. A failed ride request at an airport late at night feels entirely different emotionally. Incorrect ETAs create stress. Location inaccuracies create confusion. Payment failures create distrust. Operational failures become immediately visible because they intersect directly with real-world movement.
This changes how reliability must be approached architecturally. Reliability is not only about uptime percentages or infrastructure health metrics. It becomes deeply tied to user perception and emotional confidence in the platform itself. Small failures compound quickly because transportation systems operate inside high-trust interactions.
The challenge is that failures in distributed mobility systems are often partial rather than absolute. A driver location may lag slightly. ETA calculations may drift temporarily. Event propagation delays may create localized inconsistency. The infrastructure can remain technically operational while user confidence deteriorates behaviorally.
This is one reason mobility systems invest heavily in redundancy, graceful degradation, and operational monitoring. Reliability must exist not only at the infrastructure layer, but also at the coordination layer where humans experience uncertainty directly.
In systems built around movement, trust becomes part of the architecture.
Traditional web applications vs mobility systems
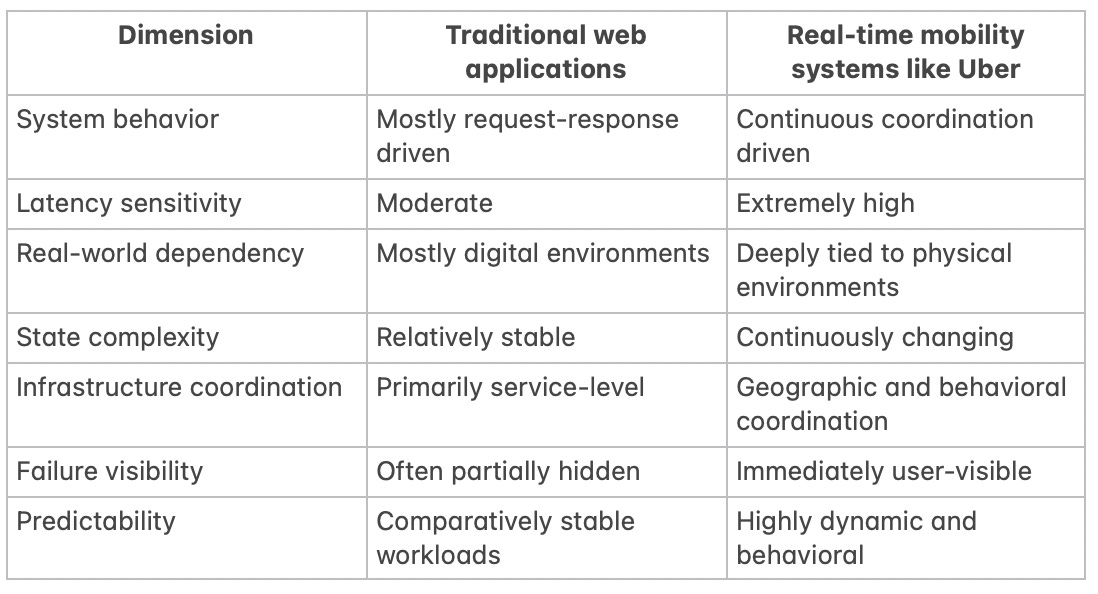
The comparison highlights why mobility systems create fundamentally different engineering challenges. Traditional applications mostly manage information. Mobility platforms manage continuously evolving coordination environments. The infrastructure must react dynamically to movement, timing, geography, and human behavior simultaneously.
This is why scaling Uber is not simply a traffic problem. It is a coordination problem operating across distributed physical systems.
Why scaling Uber is not just a traffic problem
Scaling mobility platforms introduces organizational and operational complexity far beyond raw request volume. Each city behaves differently operationally. Regulatory environments differ regionally. Infrastructure reliability varies across markets. Traffic patterns, rider behavior, driver incentives, and mapping accuracy all shift geographically.
This forces the architecture toward regional partitioning strategies where localized optimization becomes necessary. Systems must adapt to different demand characteristics, transportation norms, and operational constraints simultaneously while maintaining global consistency at the platform level.
The organizational side becomes equally important. Infrastructure teams, mapping systems, pricing systems, fraud detection systems, and market operations teams all interact continuously. Scaling the platform therefore means scaling coordination between people as much as coordination between services.
Large-scale distributed systems eventually become organizational systems too.
Observability becomes mission-critical
Debugging distributed mobility systems is unusually difficult because failures propagate across asynchronous event streams, geographical partitions, and continuously changing environmental state. Observability becomes essential not only for infrastructure monitoring, but for understanding how coordination behavior evolves operationally across the system.
Tracing systems reconstruct distributed workflows across services. Monitoring systems surface latency anomalies, matching failures, and regional degradation patterns. Event visibility becomes critical because understanding system state requires reconstructing evolving coordination flows across asynchronous infrastructure.
Location updates arrive asynchronously
Events propagate differently across regions
Small failures compound quickly
The difficult part is that operational visibility itself becomes fragmented at scale. A minor synchronization delay may appear harmless locally while producing larger behavioral distortions elsewhere in the platform. Observability systems therefore evolve into coordination analysis systems rather than simple infrastructure dashboards.
Understanding what happened becomes almost as difficult as preventing failures themselves.
Misconceptions about Uber-like systems
One common misconception is that ride-sharing systems are essentially “maps plus payments.” In reality, mapping and payments are only components inside a much larger coordination environment involving dynamic matching, event-driven orchestration, real-time positioning, market balancing, behavioral incentives, and distributed reliability systems.
Another misconception is that scaling mostly involves handling traffic volume. Traffic matters, but coordination complexity matters more. Matching riders and drivers under changing geographical and behavioral constraints is significantly harder than ordinary horizontal request scaling.
There is also a tendency to assume ride-sharing systems are “solved problems” because the interfaces appear mature. Operationally, these systems remain deeply difficult because the underlying environment never stabilizes completely. Cities change. Human behavior changes. Infrastructure conditions change. Coordination systems operating in physical environments continuously encounter new edge cases.
And importantly, cloud infrastructure alone does not solve these problems automatically. Elastic compute helps with scalability. It does not eliminate coordination complexity, environmental unpredictability, or behavioral feedback loops.
What Uber reveals about modern distributed systems
Systems like Uber reveal a broader shift happening across software architecture generally. Increasingly, modern distributed systems are not simply serving static information or processing isolated requests. They are coordinating dynamic environments in real time.
Modern distributed systems increasingly behave less like applications and more like continuously adapting coordination environments.
This pattern extends beyond mobility platforms. Logistics systems, delivery platforms, financial exchanges, real-time marketplaces, and IoT infrastructures increasingly operate through continuous event coordination rather than static transaction processing. The architecture becomes adaptive because the environment itself changes continuously.
Mobility systems are particularly fascinating because they expose this transition so clearly. They force engineers to confront what happens when distributed systems interact directly with physical movement, human unpredictability, and real-time coordination pressure simultaneously.
And honestly, software engineering still feels relatively early in learning how to build these systems well.
The future of mobility system architecture
The future of mobility infrastructure will likely involve increasingly adaptive coordination systems. Predictive routing models, AI-assisted matching optimization, real-time orchestration engines, and increasingly autonomous coordination layers will gradually reshape how transportation systems operate operationally.
But the deeper challenge probably will not be building more intelligent algorithms alone. It will be building systems capable of coordinating uncertainty responsibly at larger scales. Autonomous systems increase complexity rather than eliminating it entirely because unpredictability remains embedded inside physical environments themselves.
Infrastructure will likely become more event-driven, more predictive, and more geographically adaptive over time. But the fundamental systems challenge remains coordination under uncertainty.
And uncertainty scales poorly.
Conclusion: systems built around movement and uncertainty
Uber is architecturally fascinating because it represents something larger than a transportation app. It is a distributed coordination system operating inside continuously changing physical environments where timing, geography, infrastructure reliability, and human behavior all interact simultaneously.
The difficulty is not simply scaling traffic or serving requests. The difficulty is maintaining operational coordination while reality itself keeps changing underneath the system. Drivers move. Riders move. Cities evolve. Demand fluctuates unpredictably. Infrastructure conditions shift continuously.
This is what makes mobility systems fundamentally different from many traditional web architectures. They are not just information systems. They are systems built around movement, uncertainty, and real-time adaptation.
The most difficult distributed systems are rarely the ones serving static information. They’re the ones trying to coordinate constantly changing reality in real time.