

Why Ticketmaster System Design is harder than most distributed systems
The internet’s most stressful five minutes

There’s a very specific kind of chaos that happens during a major ticket release. You can almost feel it before the system even opens. Tens of thousands, sometimes millions, of people sitting in browser tabs refreshing the same page, all trying to acquire the same scarce resource at the exact same moment. It’s one of the few remaining experiences on the internet where collective urgency still exists in synchronized form.
Everyone shows up at once. Everyone believes timing matters. Everyone thinks they still have a chance. And then the system starts bending under pressure.
Pages stall. Queues freeze. Sessions expire. Inventory appears and disappears unpredictably. Users get kicked out after waiting an hour. Social media fills with screenshots of errors within minutes. Somewhere deep inside the infrastructure, distributed coordination mechanisms are fighting to maintain consistency while traffic spikes harder than almost any normal web application ever experiences.
Most distributed systems fail quietly. Ticketing systems fail in public.
That’s what makes systems like Ticketmaster so interesting from an engineering perspective. They expose the limits of modern infrastructure in a way most applications never do. This isn’t “just another e-commerce system,” even though people often frame it that way. Buying a concert ticket looks superficially similar to buying shoes online, but the system behavior underneath is fundamentally different. Scarcity changes everything. Human behavior changes everything. The synchronization of demand changes everything.
And unlike many system design operations, ticketing platforms operate under emotional pressure, not just technical pressure. Nobody calmly retries later when tickets disappear in seconds. The infrastructure isn’t just serving requests—it’s managing collective frustration at internet scale.
The illusion that ticketing is simple
From the outside, ticketing systems appear deceptively straightforward. A venue has seats. Users pick seats. Users pay. Inventory decreases. End of story. Compared to something like distributed databases or global messaging systems, the interface feels almost embarrassingly simple.
That illusion disappears the moment demand becomes synchronized.

The complexity of Ticketmaster-like systems doesn’t come from complicated business logic. It comes from extreme coordination under contention. The system has to maintain a globally consistent understanding of inventory while millions of users aggressively compete for the same finite resources in real time. That’s not normal web traffic. That’s closer to a distributed resource allocation problem happening in public under intense scrutiny.
Most applications are optimized around relatively predictable patterns. Traffic fluctuates gradually. Demand distributes naturally across products and time zones. Users tolerate minor delays because alternatives exist. Ticketing systems don’t get those luxuries. Demand concentrates around exact timestamps, specific artists, specific venues, and extremely small inventory windows.
The system isn’t serving “customers browsing products.” It’s handling synchronized digital panic.
And that changes almost every architectural assumption.
Scarcity changes everything
Scarcity is what transforms ticketing systems from ordinary transactional infrastructure into something much more volatile. The moment inventory becomes severely limited relative to demand, user behavior changes dramatically. Rational browsing disappears. Refresh behavior intensifies. Retry storms begin. Every millisecond suddenly feels meaningful to users, even if the backend reality is far messier than that perception.
The system stops behaving like a store and starts behaving like a contested resource market.
Everyone arrives at once
Everyone wants the same resource
Nobody tolerates delays or inconsistency
That combination is catastrophic for distributed systems.
Most internet infrastructure benefits from probabilistic spreading of activity. Ticket drops create the opposite effect: perfect synchronization. Millions of users generate near-identical traffic patterns simultaneously, often targeting the same inventory objects. That produces concentrated hotspots at every layer of the stack—databases, caches, queues, session systems, payment workflows, inventory coordinators.
And scarcity amplifies emotional behavior. Users don’t passively consume the system. They attack it unintentionally through desperation. Multiple tabs. Repeated refreshes. Rapid retries. Session hopping. Every user behaves like a mild denial-of-service actor without realizing it.
The infrastructure isn’t just fighting scale. It’s fighting synchronized human anxiety.
Real-time contention and distributed coordination
The hardest technical problem inside systems like Ticketmaster is deceptively simple to describe:
How do you guarantee that one seat gets sold to exactly one person while millions of users are trying to claim it simultaneously?
That sounds trivial until you actually try to enforce it globally at scale.
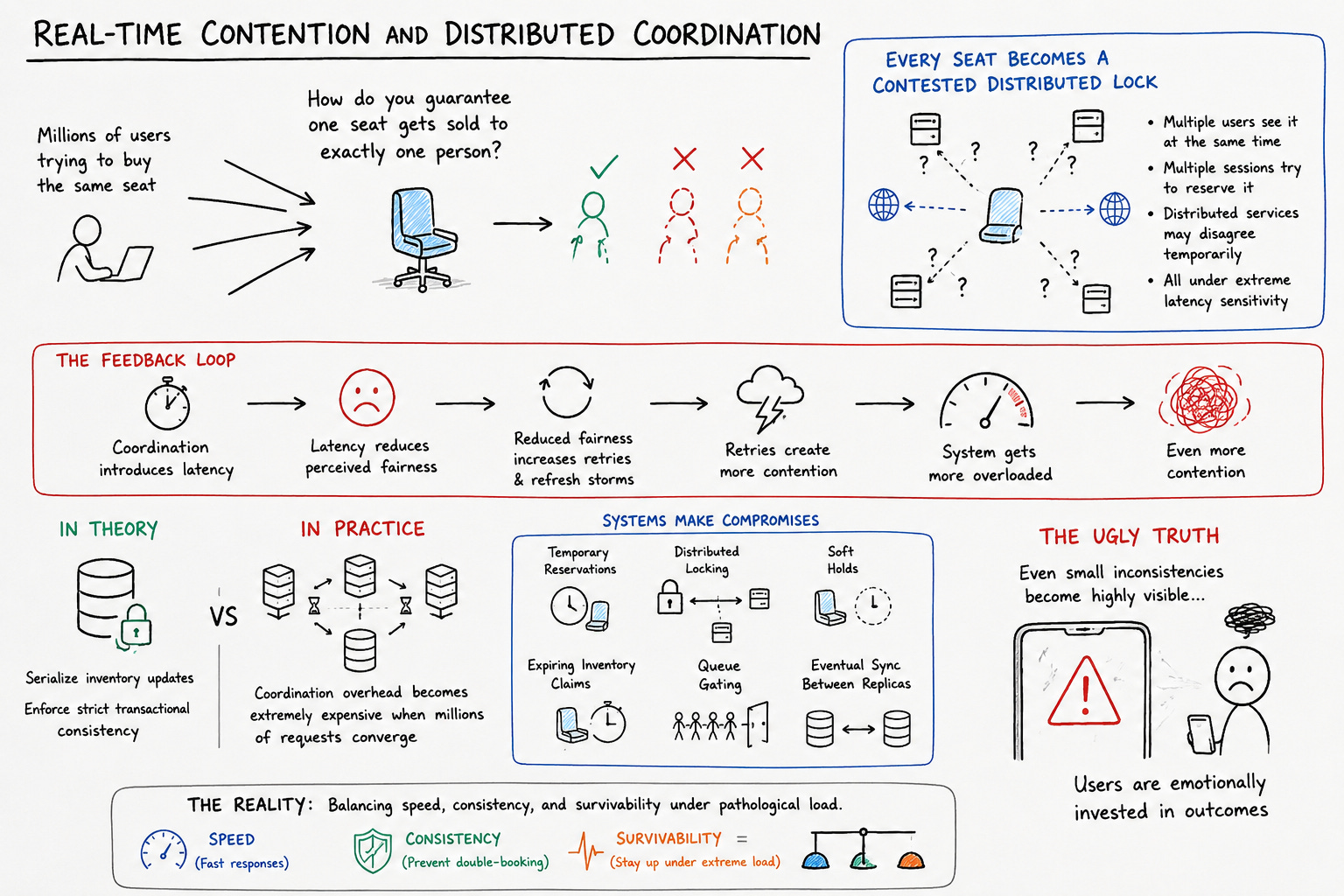
The moment inventory becomes limited, every seat effectively becomes a contested distributed lock. Multiple users can see it simultaneously. Multiple sessions can attempt to reserve it simultaneously. Multiple geographically distributed services may temporarily disagree about its state. And all of this happens under extreme latency sensitivity because users interpret delay as unfairness.
Preventing double-booking requires coordination, but coordination introduces latency. Latency reduces perceived fairness. Reduced fairness increases retries and refresh storms. Those retries create more contention.
This is where clean interview diagrams completely collapse under real-world pressure.
In theory, you can serialize inventory updates and enforce strict transactional consistency. In practice, that coordination overhead becomes extremely expensive when millions of requests converge simultaneously. So systems start making compromises. Temporary reservations. Distributed locking. Soft holds. Expiring inventory claims. Queue gating. Eventual synchronization between replicas.
None of these mechanisms are perfect. They’re all attempts to balance speed, consistency, and survivability under pathological load.
And the uglier truth is that even small inconsistencies become highly visible because users are emotionally invested in outcomes.
Queues as both infrastructure and psychology
Virtual queues are one of the most fascinating aspects of ticketing systems because they serve two completely different purposes simultaneously.
Technically, queues are load regulation systems. They smooth traffic spikes, protect downstream services, and prevent infrastructure collapse. But psychologically, they’re also fairness theater.
In systems like Ticketmaster, the queue is part infrastructure, part crowd control.
Users don’t just want access. They want perceived fairness. They need to believe the process is orderly, even if the underlying infrastructure is highly probabilistic and imperfect. The queue becomes a social contract between the platform and its users.
That’s why queue behavior matters so much beyond pure throughput optimization. Randomness feels unfair. Sudden jumps feel unfair. Freezes feel unfair. Even if the backend is technically functioning correctly, user trust erodes the moment the queue appears inconsistent.
In reality, many queue systems are doing far more than simply placing users in line. They’re segmenting traffic, prioritizing verified users, throttling suspicious behavior, coordinating admission rates with backend health, and dynamically adjusting based on inventory conditions.
The queue isn’t just protecting the infrastructure.
It’s protecting the perception of legitimacy.
The bot problem and adversarial traffic
Most web applications operate under relatively cooperative assumptions. Ticketing systems absolutely do not.
The moment high-demand events become financially valuable, the platform enters adversarial territory. Scalpers, automated buyers, browser farms, distributed bot networks, and scripted purchasing workflows all begin targeting the system aggressively. Suddenly, the infrastructure isn’t merely serving users—it’s defending itself against economically motivated automation.
This changes architectural priorities dramatically.
Anti-bot systems introduce friction intentionally. CAPTCHAs, behavioral analysis, device fingerprinting, rate limiting, identity verification, session validation—these mechanisms all exist to slow down adversarial actors. But they also degrade the experience for legitimate users.
That’s the uncomfortable trade-off ticketing systems constantly navigate:
The more aggressively you defend against bots, the more legitimate humans get caught in the blast radius.
And sophisticated bots increasingly behave like humans anyway. They simulate mouse movement, distribute requests geographically, rotate sessions, mimic browsing patterns, and adapt quickly to new defenses. It becomes an arms race where infrastructure must continuously evolve against automated adversaries with direct financial incentives.
This is why simplistic critiques of ticketing platforms often miss the reality of the environment they operate in. The system isn’t just overloaded. It’s actively under attack during major events.
Caching, replication, and stale reality
In most large-scale systems, aggressive caching is one of the easiest ways to improve performance. Ticketing systems complicate that assumption because stale data becomes emotionally explosive.
If inventory data propagates slowly across replicas or caches, users see seats that no longer exist. They click available tickets that disappear during checkout. They believe the platform is broken or manipulative. Even tiny synchronization delays create visible frustration because users interpret stale inventory as deception.
Caching suddenly becomes dangerous.
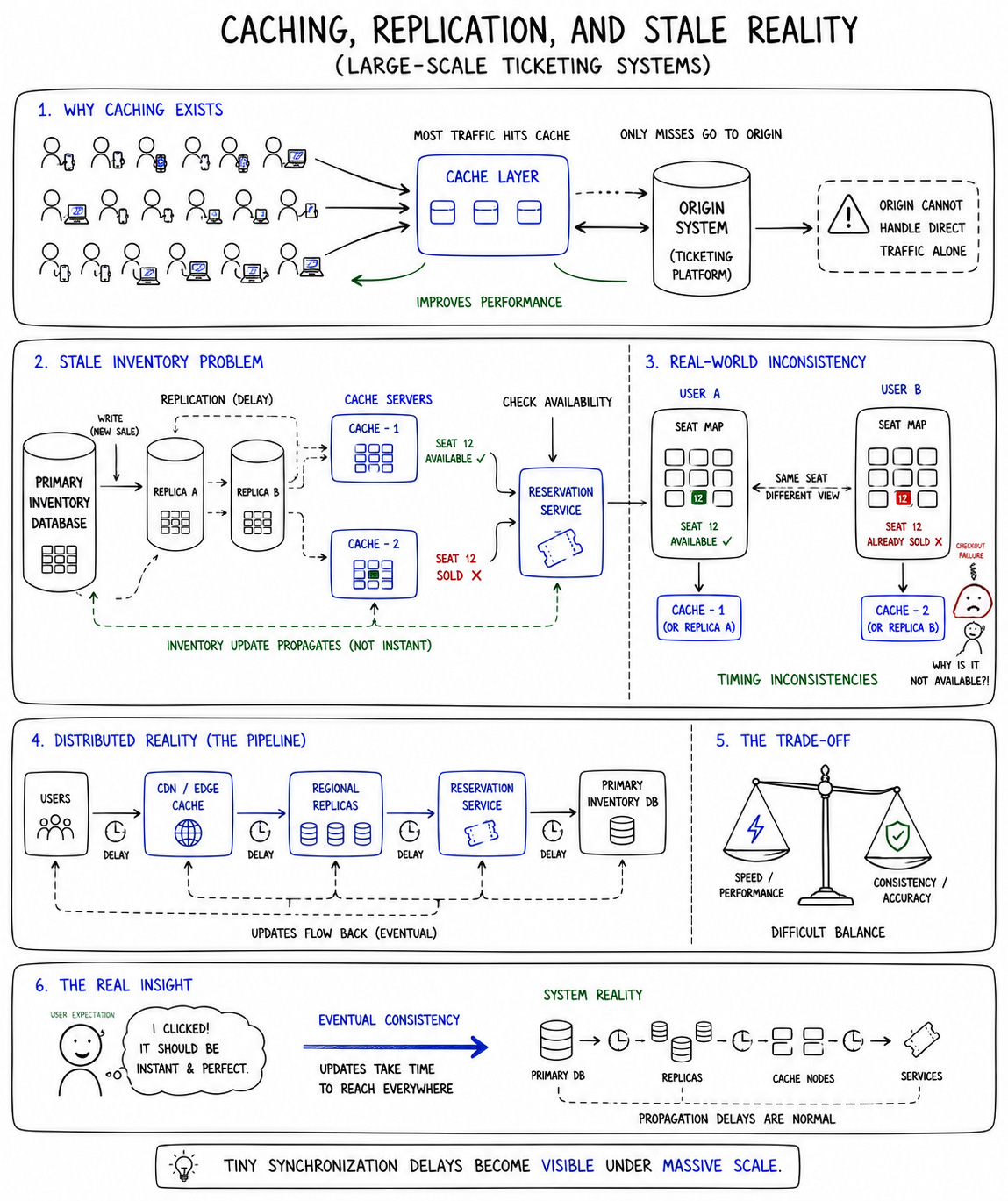
The problem is that you still need caching because origin systems cannot survive direct traffic at this scale. So platforms end up operating in an uncomfortable middle ground where they aggressively cache some data while carefully coordinating highly volatile inventory states closer to real time.
But “real time” in distributed systems is always messier than users imagine.
Inventory state propagates through layers of caches, replicated databases, reservation services, and geographically distributed infrastructure. During peak load, tiny timing inconsistencies become amplified into visible user-facing failures.
And users don’t care about eventual consistency models when they lose seats during checkout.
The infrastructure cost of rare events
One of the least appreciated aspects of Ticketmaster-like systems is how economically inefficient they are by nature.
Most systems optimize around relatively stable utilization. Ticketing systems optimize around catastrophic spikes that happen briefly but unpredictably. Infrastructure must survive massive synchronized surges that may last minutes or hours, even if average daily traffic is far lower.
That creates an ugly operational reality: enormous infrastructure capacity exists primarily for rare moments of collective urgency.
Cloud elasticity helps, but only partially. Scaling infrastructure reactively during explosive demand spikes is harder than people assume. Database coordination, queue systems, session management, inventory locking, and replication delays don’t magically disappear because compute instances scale horizontally.
The hardest bottlenecks are often stateful systems, not stateless application servers.
And provisioning for worst-case load is expensive. Very expensive.
Traditional e-commerce vs ticketing systems
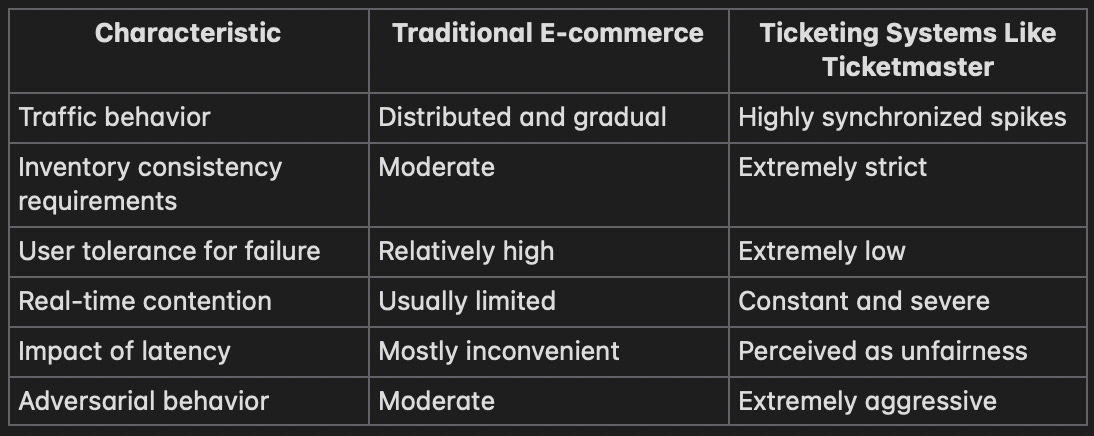
This is why comparing Ticketmaster to ordinary shopping platforms misses the point entirely.
Traditional e-commerce systems benefit from diversification. Users browse different products, arrive at different times, and tolerate retries reasonably well. Ticketing systems experience concentrated warfare around identical inventory objects with emotionally charged users operating under severe scarcity.
The architecture isn’t just handling transactions. It’s handling synchronized contention at internet scale.
And synchronized contention is one of the hardest problems in distributed systems.
Trade-offs at the center of ticketing platforms
Every major design decision inside systems like Ticketmaster revolves around uncomfortable trade-offs.
Fairness vs speed
Availability vs consistency
Security vs user experience
Scalability vs operational cost
Strict consistency improves inventory correctness but increases latency. Aggressive anti-bot protections improve fairness but frustrate legitimate users. Large virtual queues protect infrastructure but create public anger. Relaxed synchronization improves throughput but risks overselling inventory.
There are no clean solutions here. Only compromises.
And those compromises become highly visible because users interact with the system during emotionally significant moments. Nobody cares about distributed systems theory when they fail to buy tickets after waiting three hours.
Failure in public
Most infrastructure failures remain invisible outside engineering teams. Ticketing failures become national conversations.
Nobody tweets when a background service crashes. They absolutely tweet when they can’t buy concert tickets.
That visibility changes operational pressure enormously.
Every outage becomes public theater. Every queue freeze generates screenshots. Every error message spreads instantly across social platforms. Infrastructure failures become cultural events because the affected users are emotionally invested and simultaneously online.
This creates extraordinary pressure on incident response teams. The system isn’t merely failing technically—it’s failing socially in real time under public scrutiny.
And unlike internal enterprise systems, there’s no graceful degradation path that users quietly accept. Ticketing failures directly collide with anticipation, money, scarcity, and disappointment all at once.
That’s a uniquely brutal operational environment.
Misconceptions about systems like Ticketmaster
The internet loves simplistic explanations for ticketing failures.
“Just add more servers.”
“Use the cloud properly.”
“This is just bad engineering.”
Those critiques sound satisfying, but they dramatically underestimate the complexity of coordinated contention systems.
Adding more stateless servers doesn’t solve distributed locking bottlenecks. Cloud scaling doesn’t eliminate consistency trade-offs. Perfect fairness isn’t technically achievable under massive synchronized demand. And anti-bot protections inherently create friction for real users too.
The harder truth is that these systems operate near the boundaries of what distributed coordination can realistically handle under adversarial conditions.
That doesn’t mean platforms are beyond criticism. It means the problem itself is fundamentally ugly.
What Ticketmaster reveals about modern distributed systems
Ticketing platforms expose something important about large-scale systems generally:
The hardest problems usually aren’t about serving content. They’re about coordinating scarce state under unpredictable human behavior.
Interview diagrams simplify distributed systems into neat boxes and arrows. Real systems are full of retries, race conditions, overloaded dependencies, stale replicas, partial failures, adversarial traffic, and emotional users behaving irrationally under pressure.
Ticketmaster-like systems make those realities impossible to ignore because the failure modes are public and immediate.
They remind us that distributed systems are ultimately sociotechnical systems. Infrastructure behavior cannot be separated from human behavior because humans adapt to the system continuously, often in destructive ways.
The future of large-scale ticketing systems
The next generation of ticketing infrastructure will probably become increasingly identity-driven and behavior-aware. AI-assisted traffic analysis, adaptive queue admission, stronger identity verification, device reputation systems, and more aggressive bot detection will continue evolving because the economic incentives are too strong not to.
But none of that fully solves the deeper issue.
The underlying problem is synchronized scarcity itself. When millions of people want the same limited thing at the same moment, no architecture can make the experience feel completely fair to everyone. Infrastructure can mitigate contention, regulate flow, and improve resilience, but it cannot eliminate disappointment.
And that’s the uncomfortable reality beneath these systems.
They aren’t just selling tickets.
They’re managing collective urgency at internet scale.
Conclusion: systems built around moments of collective urgency
Ticketmaster is fascinating because it reveals how fragile distributed systems become when scarcity, synchronization, and human emotion collide simultaneously.
The hardest part isn’t serving pages or processing payments. Modern infrastructure is already very good at that. The hard part is maintaining fairness, consistency, trust, and survivability while millions of users aggressively compete for the same finite resources in real time.
That’s what makes ticketing systems fundamentally different from ordinary web applications.
They are systems designed around moments of collective urgency.
And moments of collective urgency tend to break things.