

Machine Learning in a hurry and the fear of falling behind
Everyone suddenly needs to know machine learning

Something changed very quickly over the last few years, and I don’t think the industry has fully processed what happened.
Machine learning used to occupy a fairly specialized corner of software engineering. There were researchers, data scientists, infrastructure teams supporting models at scale, and a relatively small number of engineers working directly on ML systems. Most developers could safely ignore the field without feeling professionally vulnerable. That boundary disappeared faster than most people expected.
By 2026, machine learning stopped feeling like an optional specialization and started feeling like ambient career pressure. Backend engineers suddenly needed to understand embeddings. Frontend developers were integrating copilots into workflows they barely understood themselves. Infrastructure engineers were being asked about vector databases and inference latency in meetings that had nothing to do with traditional ML. Product roadmaps became saturated with “AI-first” language almost overnight.
And because the transition happened so quickly, many engineers developed the same quiet feeling simultaneously: the feeling that everyone else somehow already understands this.
The hardest part about learning machine learning today isn’t the complexity. It’s the speed at which everyone expects you to understand it.
Over the last few years at Educative, I’ve watched this pressure show up repeatedly in how engineers approach learning. Not calmly. Not methodically. Usually in bursts of panic-driven acceleration. People trying to compress years of foundational understanding into weekends, late-night study sessions, or hurried learning sprints between meetings and production incidents.
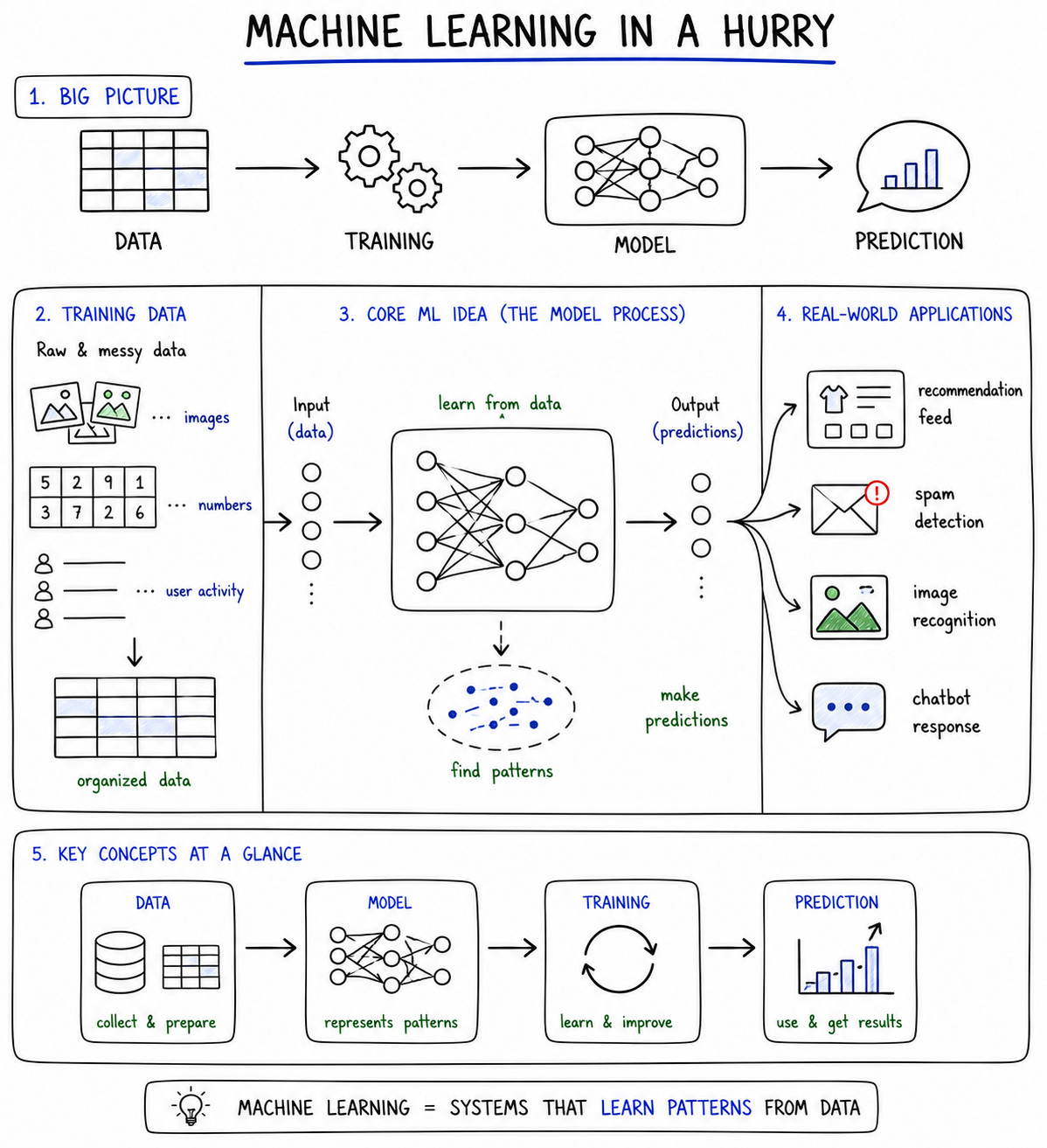
What makes this difficult is not simply the amount of information. Software engineers are already accustomed to large technical domains. The harder part is that machine learning arrived wrapped in a cultural expectation of urgency. The industry stopped treating ML as something you gradually grow into and started treating it as something you should already know.
That changes how people learn. Usually not for the better.
The industry’s obsession with acceleration
One of the more exhausting aspects of the AI era is how aggressively it compresses expectations around learning.
Every new framework, model release, orchestration layer, or infrastructure abstraction arrives with the implication that immediate familiarity is necessary for professional relevance. Engineers don’t just encounter new ideas anymore. They encounter new ideas accompanied by collective anxiety.
The ecosystem moves fast enough that people rarely feel finished understanding one concept before the industry pivots toward another. One month everyone is discussing prompt engineering. Then retrieval-augmented generation dominates conversations. Then agents. Then multimodal systems. Then infrastructure tooling around agents. Then model routing. Then evaluation pipelines. The abstractions accumulate faster than intuition can stabilize.
This creates a strange kind of cognitive fatigue that I think many engineers struggle to articulate properly. It’s not ordinary burnout exactly. It’s closer to the feeling of perpetually running behind a moving train while the people already on board insist the train is easy to catch.
And because modern technical culture rewards visible participation, people often respond by increasing consumption rather than understanding. More newsletters. More videos. More podcasts. More tutorials. More “10 things every AI engineer must know” threads written with absolute certainty about technologies that barely existed six months earlier.
The result is that many developers end up technically saturated but conceptually fragmented.
The illusion of “catching up”
One thing I’ve observed repeatedly is that machine learning creates an unusually strong illusion of progress.
You can consume a tremendous amount of ML content very quickly. You can recognize terminology within days. You can follow architectural diagrams after a few weeks. You can become conversationally functional surprisingly fast. And because the internet rewards familiarity signals, that surface-level understanding often feels deeper than it really is.
But machine learning resists compression in ways many people underestimate.
There’s a difference between understanding what a transformer architecture is and understanding why large-scale ML systems behave unpredictably under real-world constraints. There’s a difference between recognizing terms like embeddings, fine-tuning, and inference pipelines and developing intuition about how these systems fail, drift, degrade, or interact operationally.
Rapid content consumption creates confidence before it creates mental models.
That distinction matters.
The engineers who struggle most are often not the ones who know the least. They’re the ones who mistake familiarity for understanding and then become frustrated when deeper reasoning still feels inaccessible. They can follow explanations while consuming them, but cannot reconstruct the ideas independently afterward.
And honestly, that’s not a personal failure. It’s a predictable consequence of how modern technical learning environments operate.
What developers are actually struggling with
After watching thousands of engineers move through ML learning material, certain patterns appear repeatedly.
The confusion is often less about mathematics than people assume. More commonly, it comes from systems thinking gaps. Engineers understand isolated concepts but struggle to connect them into coherent behavior.
People understand the words but not the systems
They recognize architectures without understanding trade-offs
They consume information faster than they process it
This shows up constantly around probabilistic behavior. Traditional software engineering trains people to expect deterministic systems. Inputs produce predictable outputs. Logic behaves consistently. Failures can usually be reproduced.
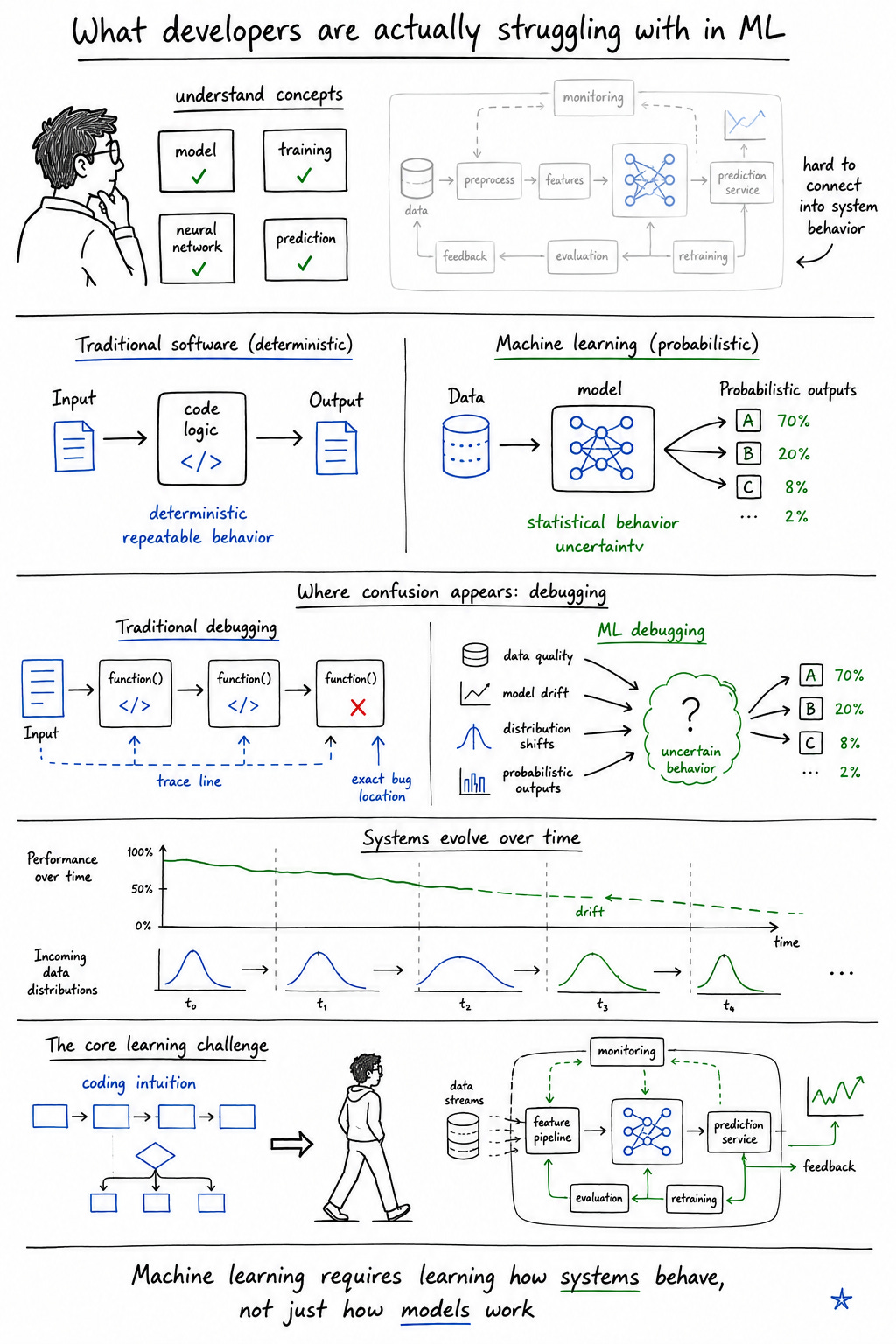
Machine learning systems violate those expectations constantly.
Models behave statistically rather than deterministically. Performance degrades gradually. Data quality influences outcomes in nonlinear ways. Systems drift over time. Small distribution shifts create unexpected behavior. Suddenly engineers aren’t just debugging code anymore—they’re debugging uncertainty.
That changes the learning experience fundamentally because it requires a different kind of intuition than traditional application development.
Why structured learning became necessary
Part of the reason we built resources like Fundamentals of Machine Learning for Software Engineers was because we kept seeing the same pattern repeatedly: engineers drowning in disconnected information while lacking conceptual continuity.
One thing we realized early is that most developers do not need more hype-driven summaries. They need structure. They need explanations that connect ideas gradually instead of treating machine learning as a collection of isolated buzzwords.
The same pattern appeared with Machine Learning System Design. A lot of developers were learning models abstractly without understanding how ML systems actually behave in production environments. But production ML is not just about algorithms. It’s about infrastructure, latency, data pipelines, observability, drift, scaling constraints, and operational trade-offs.
And interview pressure amplified this further, which is partly why courses like Grokking the Machine Learning Interview emerged. Not because interviews represent ideal learning environments—they absolutely do not—but because engineers increasingly felt pressure to perform ML fluency publicly before their understanding fully matured.
Even the Key Principles of Machine Learning Every Developer Should Know blog came from observing the same recurring confusion: people trying to absorb advanced abstractions without stable mental models underneath.
The goal was never to simplify machine learning into something artificial. It was to reduce unnecessary chaos around the learning process itself.
Machine learning feels different because it behaves differently
I think one reason machine learning creates so much discomfort for traditional engineers is that the systems themselves violate deeply ingrained expectations about software behavior.
Conventional systems engineering revolves around precision. You design explicit logic paths. You reason deterministically. Failures are usually traceable through code and infrastructure. Machine learning introduces systems that behave probabilistically, adapt dynamically, and sometimes produce outputs that are difficult to explain fully even when the implementation is technically correct.
That ambiguity changes how people learn.
Engineers accustomed to deterministic reasoning often experience ML as conceptually slippery. You can understand the architecture and still feel uncertain about the behavior. You can understand the pipeline and still feel unclear about the outputs. The systems resist tidy mental compression because the behavior itself emerges statistically rather than logically.
And that uncertainty becomes psychologically difficult in an industry obsessed with confidence signaling.
The pressure to become AI-native
Somewhere between 2023 and 2026, machine learning quietly stopped being optional knowledge.
Somewhere between 2023 and 2026, machine learning quietly stopped being optional knowledge.
That transition happened unevenly, but the cultural effect was enormous.
Suddenly ML awareness became expected even for engineers who never intended to specialize in machine learning directly. Backend engineers felt pressure to understand retrieval systems. Frontend developers were integrating AI features into products. Infrastructure teams were expected to reason about inference costs and vector search latency.
The result is that many engineers now experience machine learning less as curiosity and more as professional obligation.
And obligation changes the emotional texture of learning. People stop learning because they’re fascinated and start learning because they’re afraid of becoming obsolete.
That fear rarely gets discussed honestly, but it’s present everywhere.
Interview culture and performance anxiety
Interview culture intensified all of this considerably.
The rise of ML-focused interview preparation created another layer of pressure because engineers increasingly felt expected to demonstrate machine learning fluency performatively, often before developing durable intuition.
That’s partly why resources like Grokking the Machine Learning Interview resonated with people. Structured interview preparation provides emotional reassurance in uncertain environments. It gives the impression that machine learning can be organized into recognizable patterns and predictable expectations.
But there’s also a danger there.
Memorization creates temporary fluency. Real understanding develops much more slowly.
And machine learning interviews sometimes reward the former while actual engineering work depends heavily on the latter.
This creates an uncomfortable mismatch where people optimize for sounding informed before they feel genuinely grounded conceptually.
The difference between consuming information and building understanding

What this table really highlights is that genuine understanding often feels slower and emotionally less satisfying initially.
Fast content consumption produces immediate familiarity and conversational fluency. Structured learning feels slower because it prioritizes conceptual continuity over novelty. Long-term understanding feels slowest of all because it requires ambiguity, repetition, confusion, and gradual mental model formation.
Unfortunately, modern internet culture disproportionately rewards the first category while actual engineering capability depends much more heavily on the last one.
Trade-offs in learning ML quickly
Every engineer learning machine learning today is navigating the same difficult tensions.
Speed vs depth
Breadth vs intuition
Trend awareness vs fundamentals
There’s no perfect balance here.
Move too quickly and understanding fragments into disconnected abstractions. Move too slowly, and the ecosystem evolves around you faster than your confidence stabilizes. Focus only on trends, and fundamentals remain weak. Focus only on fundamentals, and you risk feeling disconnected from industry conversations.
The pressure comes partly from trying to optimize all of these simultaneously, which is usually impossible.
The emotional side of modern technical learning
I think many engineers quietly underestimate how emotionally exhausting technical acceleration has become.
Most people are learning machine learning while already working demanding jobs, dealing with deadlines, navigating layoffs, handling burnout, or trying to maintain ordinary life responsibilities. Learning doesn’t happen in calm academic environments. It happens late at night after meetings. On weekends. During fragmented periods of exhaustion.
And because the field moves so quickly, people internalize this persistent sense that slowing down equals falling behind.
What rarely gets admitted publicly is how much comparison drives modern technical anxiety. Everyone online appears to understand more than they actually do. Social media disproportionately amplifies signals of certainty, speed, and productivity while almost entirely hiding confusion and slow learning.
So engineers end up privately overwhelmed while publicly pretending to keep pace.
What actually helps over time
The developers who eventually build strong intuition usually do something counterintuitive at some point:
They slow down.
Not permanently. Not by disengaging from the field entirely. But by shifting focus away from pure consumption velocity and toward mental model formation.
Understanding starts improving once engineers stop trying to absorb every new abstraction immediately and begin organizing relationships between ideas instead. Why systems behave probabilistically. Why infrastructure constraints shape model behavior. Why data quality matters more than most people initially realize. Why trade-offs dominate production ML.
This is where structure becomes genuinely valuable—not because it accelerates expertise artificially, but because it reduces cognitive chaos enough for understanding to develop gradually.
That process is slower than hype culture encourages. But it’s also much more sustainable.
Misconceptions about learning ML in 2026
There are a few assumptions I wish more engineers would question openly.
“Everyone else already understands this.”
Most people are far more uncertain than they appear publicly.
“You need to know everything.”
The field is now too broad for comprehensive mastery to be realistic even for specialists.
“Watching enough content equals mastery.”
Consumption creates recognition. Understanding requires reflection, struggle, and time.
These distinctions matter because unrealistic expectations distort the entire learning process.
Slowing down in a field that keeps accelerating
Machine learning is genuinely difficult. Not because engineers lack intelligence, but because the systems themselves are probabilistic, fast-moving, infrastructure-heavy, and conceptually layered in ways that resist rapid compression.
And maybe the healthier realization is that confusion is not evidence of failure. It’s evidence that you are engaging with something legitimately complex.
The industry often behaves as though expertise should arrive immediately after exposure. But real understanding still develops the same way it always has: slowly, unevenly, through repetition, uncertainty, and gradual intuition-building.
That process hasn’t changed, even if the hype cycles surrounding it have accelerated dramatically.
Most engineers aren’t behind. They’re just trying to learn a field that the industry itself barely understands completely.