

Generative system design
Traditional systems execute instructions while generative systems produce possibilities.

For most of software history, systems were designed around a relatively stable assumption: software executes instructions deterministically. Engineers wrote logic, systems processed inputs, and outputs followed predictable paths through carefully controlled workflows. Even highly distributed systems ultimately behaved like enormous deterministic machines. The complexity came from scale, coordination, latency, and infrastructure management, not from the system independently generating variable outcomes. If something behaved unexpectedly, engineers assumed there was a bug somewhere in the code, the network, or the infrastructure stack.
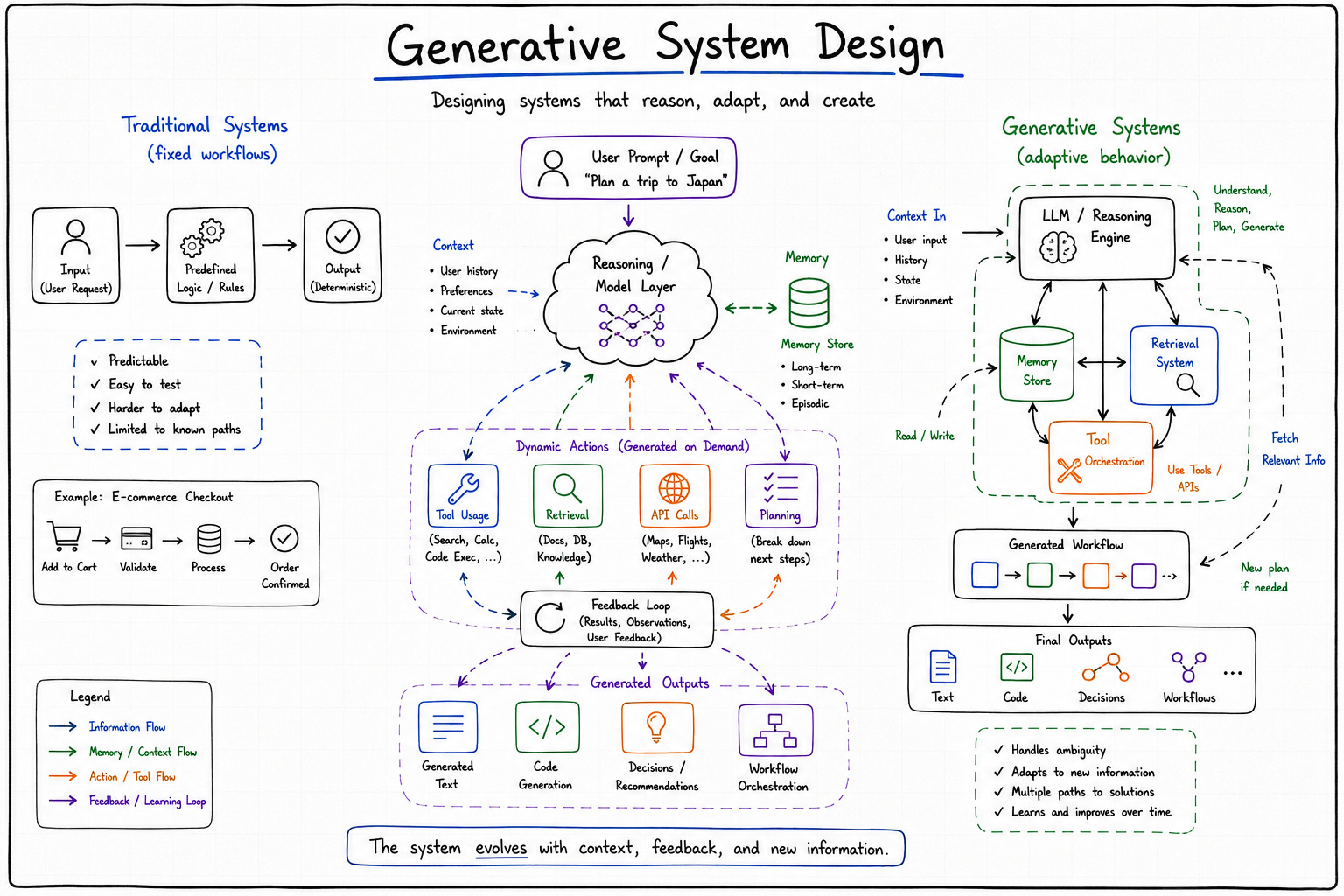
Generative systems changed that assumption quietly at first, and then all at once. Generative system design no longer simply execute instructions in predictable ways. They generate outputs probabilistically. They synthesize responses dynamically based on context, retrieval pipelines, memory systems, and continuously evolving inputs. The same prompt can produce different results under slightly different conditions. The architecture no longer revolves entirely around deterministic execution paths because the central computational layer itself behaves probabilistically.
Traditional systems execute instructions. Generative systems produce possibilities.
That shift matters more than many architectural discussions currently acknowledge. Much of modern AI discourse still treats large language models as interchangeable API layers that can simply be inserted into existing application stacks. But production generative systems behave differently enough from traditional software that they force engineers to rethink assumptions around reliability, observability, orchestration, failure handling, and even ownership of system behavior itself. The challenge is not simply adding AI to software. The challenge is designing infrastructure around systems whose behavior cannot be fully predicted ahead of time.
Why generative systems feel fundamentally different
Traditional software systems are built around explicit logic. Engineers define workflows, conditionals, execution paths, and state transitions directly. Even when systems become extremely complicated operationally, the architecture still reflects intentional deterministic behavior. The software does exactly what it was programmed to do, even if the resulting complexity becomes difficult to manage at scale. Failures usually emerge from identifiable causes because the system itself is fundamentally rule-based.
Generative systems operate differently because the central computation layer introduces probabilistic behavior directly into the architecture. Outputs emerge statistically rather than deterministically. Responses depend not only on the immediate input, but also on context windows, retrieval quality, prompt structure, model state, token constraints, and external orchestration layers. Two seemingly identical requests can produce subtly different outcomes because the system is synthesizing responses dynamically rather than retrieving predefined outputs.
This changes how engineers reason about reliability itself. Reliability in traditional systems usually means reproducibility. Given the same inputs, the system should behave consistently. In generative systems, reproducibility becomes less absolute. Engineers increasingly evaluate systems probabilistically rather than deterministically. The architecture shifts from guaranteeing exact behavior toward constraining ranges of acceptable behavior. That is a significant conceptual change for software engineering because software infrastructure historically optimized around predictability above almost everything else.
The psychological effect on engineering teams is subtle but important. Traditional systems fail in ways engineers can usually explain. Generative systems occasionally fail in ways that sound philosophical. Outputs drift semantically. Context influences behavior unexpectedly. Retrieval pipelines surface misleading information. Somewhere along the way, debugging started involving psychology.
The shift from workflows to orchestration
One of the biggest architectural changes introduced by generative systems is that orchestration became more important than isolated computation. Modern AI applications rarely consist of a single model responding independently to user requests. Instead, production systems increasingly coordinate multiple interacting components simultaneously: language models, retrieval systems, vector databases, memory layers, external APIs, evaluation pipelines, moderation systems, and policy engines.
The system no longer behaves like a traditional request-response application. It behaves more like an orchestrated environment where different subsystems continuously exchange context and influence outcomes dynamically. The architecture increasingly revolves around managing interactions between probabilistic components rather than simply scaling deterministic services.
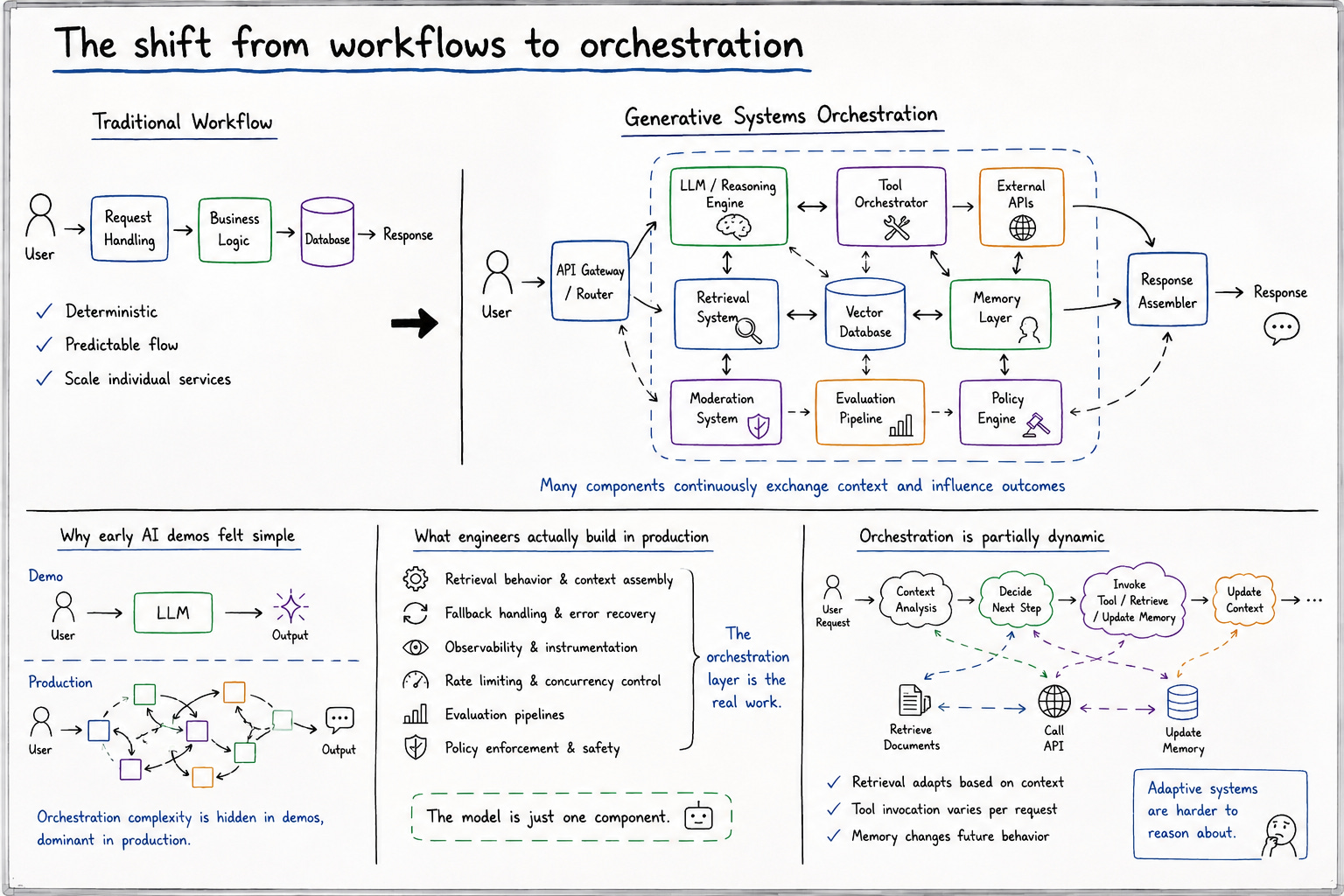
This shift explains why many early AI demos felt deceptively simple compared to production deployments. Demos often isolate the model itself while hiding the surrounding orchestration complexity entirely. In production environments, however, the orchestration layer frequently dominates the actual engineering effort. Engineers spend enormous amounts of time coordinating retrieval behavior, context assembly, fallback handling, observability instrumentation, rate limiting, evaluation pipelines, and policy enforcement systems. The model becomes only one component inside a much larger operational ecosystem.
What makes this operationally difficult is that orchestration itself becomes partially dynamic. Retrieval pipelines adapt based on context. Tool invocation varies between requests. Memory systems alter future behavior gradually over time. The architecture stops behaving like a static workflow graph and starts behaving more like an adaptive coordination system. And adaptive systems are always harder to reason about than deterministic workflows.
Context becomes infrastructure
In traditional software systems, context was usually treated as application state. In generative systems, context increasingly behaves like infrastructure itself. The quality, structure, availability, and management of context directly shape system behavior in ways that are operationally significant.
Context windows, retrieval pipelines, conversation memory, embeddings, and vector search layers now determine how generative systems reason, respond, and adapt over time. Engineers are no longer simply managing infrastructure around computation. They are managing infrastructure around understanding itself.
Context affects output quality
Retrieval affects system reliability
Memory changes system behavior over time
This introduces architectural concerns that traditional software systems rarely faced directly. Longer context windows improve coherence but increase latency and cost. Retrieval pipelines improve factual grounding but introduce dependency complexity and ranking uncertainty. Persistent memory improves continuity while simultaneously increasing behavioral unpredictability over time.
What makes context especially important is that it influences outputs indirectly rather than deterministically. The same retrieval set can lead to different responses depending on prompt structure, token allocation, model interpretation, or surrounding conversational state. Engineers increasingly optimize systems not around exact execution paths, but around probabilistic behavioral shaping.
That changes how infrastructure decisions are made. Retrieval latency becomes part of response quality. Embedding freshness becomes operationally meaningful. Context assembly pipelines influence hallucination rates. Architectural concerns that once belonged primarily to application logic now sit directly inside infrastructure conversations.
Retrieval systems quietly became part of the stack
One of the more important shifts in modern AI infrastructure is that retrieval systems moved from optional enhancement to foundational architecture. Generative systems increasingly depend on dynamically retrieved external knowledge because models alone cannot reliably encode all required information operationally.
Retrieval-augmented generation systems fundamentally change software assumptions because the system’s knowledge state becomes partially externalized. Instead of relying entirely on model weights, systems continuously fetch relevant information dynamically from vector databases, search indexes, internal documentation systems, APIs, or structured knowledge sources. The model becomes less of a standalone intelligence layer and more of a reasoning engine operating across external information environments.
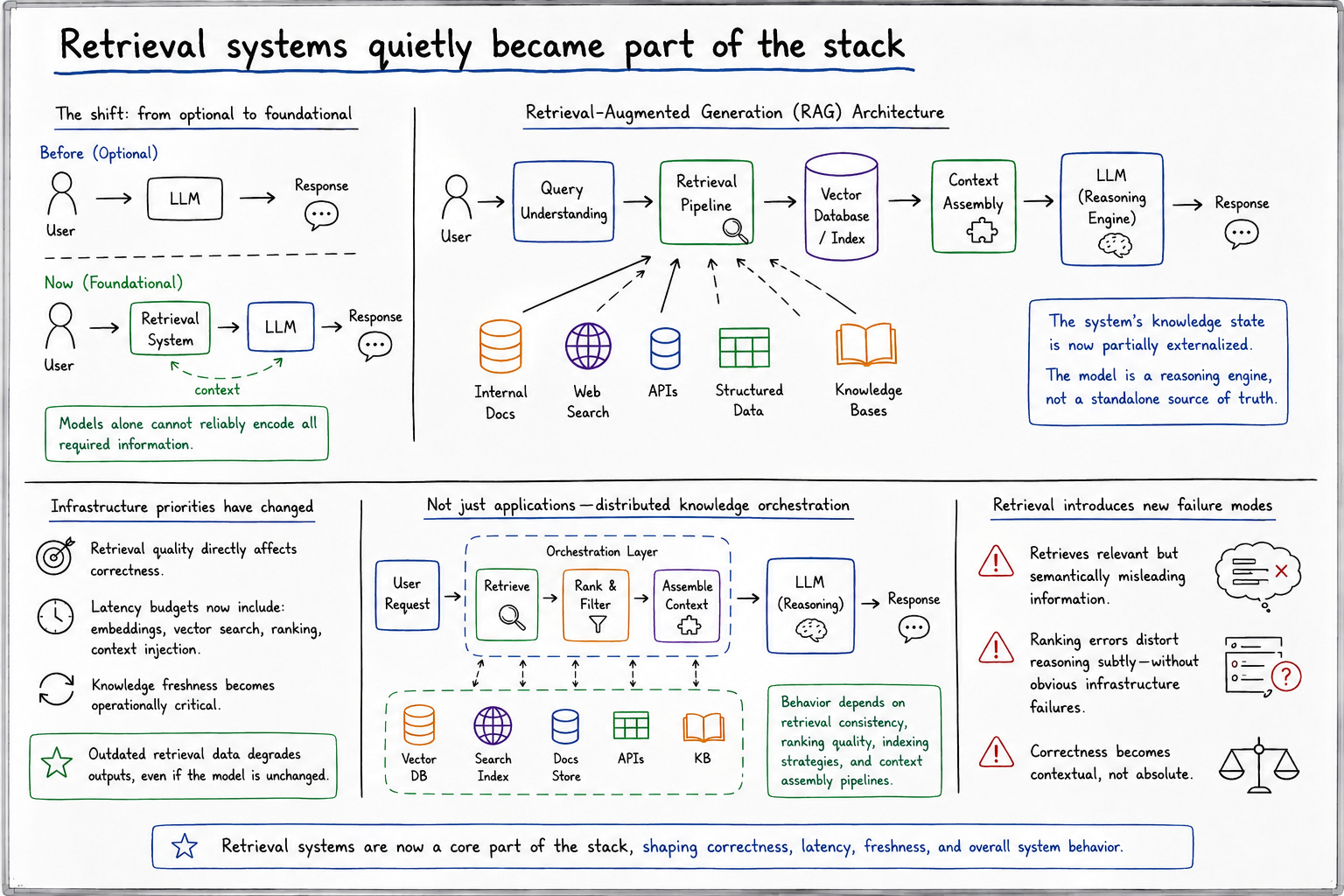
This changes infrastructure priorities significantly. Retrieval quality now directly affects system correctness. Latency budgets must include embedding generation, vector search, ranking pipelines, and context injection overhead. Knowledge freshness becomes operationally important because outdated retrieval data degrades outputs even when the model itself remains unchanged.
The result is that generative systems increasingly resemble distributed knowledge orchestration systems rather than standalone applications. Models reason across dynamically assembled information rather than static internal representations alone. That creates architectures whose behavior depends heavily on retrieval consistency, ranking quality, indexing strategies, and contextual assembly pipelines.
And importantly, retrieval introduces new failure modes. The system may retrieve technically relevant but semantically misleading information. Context ranking errors can distort reasoning subtly without producing obvious infrastructure failures. The architecture becomes increasingly dependent on systems whose correctness is contextual rather than absolute.
The operational problem nobody expected
The operational complexity of production generative systems is still widely underestimated because demos hide most of the difficult parts. Demo environments isolate models from operational reality. Production systems inherit all the complexity of distributed systems plus entirely new categories of probabilistic behavior.
Latency becomes unpredictable because inference workloads fluctuate dynamically based on context length, retrieval depth, orchestration complexity, and model routing decisions. Costs become difficult to stabilize because token consumption scales nonlinearly across workloads. Outputs vary semantically even when infrastructure remains healthy. Monitoring becomes harder because failures increasingly emerge behaviorally rather than technically.
Generative systems don’t just introduce new infrastructure problems. They introduce systems that behave differently every time you look at them.
This unpredictability creates unusual operational stress for engineering organizations. Traditional observability tooling assumes relatively stable behavioral expectations. Generative systems violate those assumptions constantly. Metrics may appear healthy while outputs degrade semantically. Infrastructure can remain fully operational while hallucination rates quietly increase due to subtle retrieval shifts or context fragmentation.
Production environments expose how much AI infrastructure revolves around behavioral management rather than raw computation. Engineers increasingly spend time evaluating outputs qualitatively, monitoring drift probabilistically, and constructing feedback systems capable of detecting semantic degradation before users notice it operationally.
The demos rarely mention any of this because operational reality is much harder to present elegantly than model capability itself.
Human oversight returns to the center
One of the more surprising consequences of generative systems is that human oversight became more important, not less. Early AI narratives often implied that increasingly capable systems would gradually reduce the need for human intervention. Operational reality moved in the opposite direction.
As generative systems became more autonomous, organizations discovered that unrestricted autonomy creates substantial reliability, legal, and trust risks. Hallucinations, reasoning inconsistencies, unsafe outputs, policy violations, and retrieval errors all introduce operational uncertainty that many environments cannot tolerate fully unattended.
As a result, modern generative architectures increasingly revolve around layered oversight mechanisms. Moderation systems filter outputs. Evaluation pipelines validate behavior. Human approval layers remain embedded inside high-risk workflows. Policy enforcement systems constrain model behavior dynamically. Observability tooling monitors semantic degradation continuously.
This is not because the models are “bad.” It is because probabilistic systems operating in real-world environments create unavoidable uncertainty. And uncertainty changes how organizations think about operational authority.
The deeper shift here is architectural. Human intervention is no longer treated merely as customer support or operational exception handling. It increasingly becomes part of the infrastructure design itself. Engineers now design systems assuming that human judgment remains necessary at specific points inside probabilistic workflows.
That represents a meaningful reversal from earlier automation narratives.
Why scaling generative systems is not just a compute problem
One misconception that still dominates AI conversations is the assumption that scaling generative systems primarily means adding more compute. Compute matters enormously, obviously, but operational scaling increasingly depends on orchestration complexity, retrieval performance, context management, caching strategies, observability systems, and cost control mechanisms.
Generative workloads scale differently from traditional software systems because inference cost grows directly with usage intensity. Every additional user may increase computational demand substantially. Longer context windows increase latency and token consumption simultaneously. Better outputs often require more retrieval depth, more orchestration layers, or more expensive reasoning pathways.
More users increase inference cost directly
Longer context increases latency
Better outputs often require more orchestration
Caching becomes complicated because outputs are probabilistic rather than deterministic. Observability becomes expensive because evaluating semantic quality requires richer instrumentation than traditional metrics systems provide. Routing decisions become operationally important because organizations increasingly optimize workloads across multiple models dynamically based on cost, latency, and reasoning quality.
Scaling generative systems therefore becomes less about pure horizontal infrastructure expansion and more about managing probabilistic coordination efficiently across interacting subsystems.
Traditional systems vs generative systems
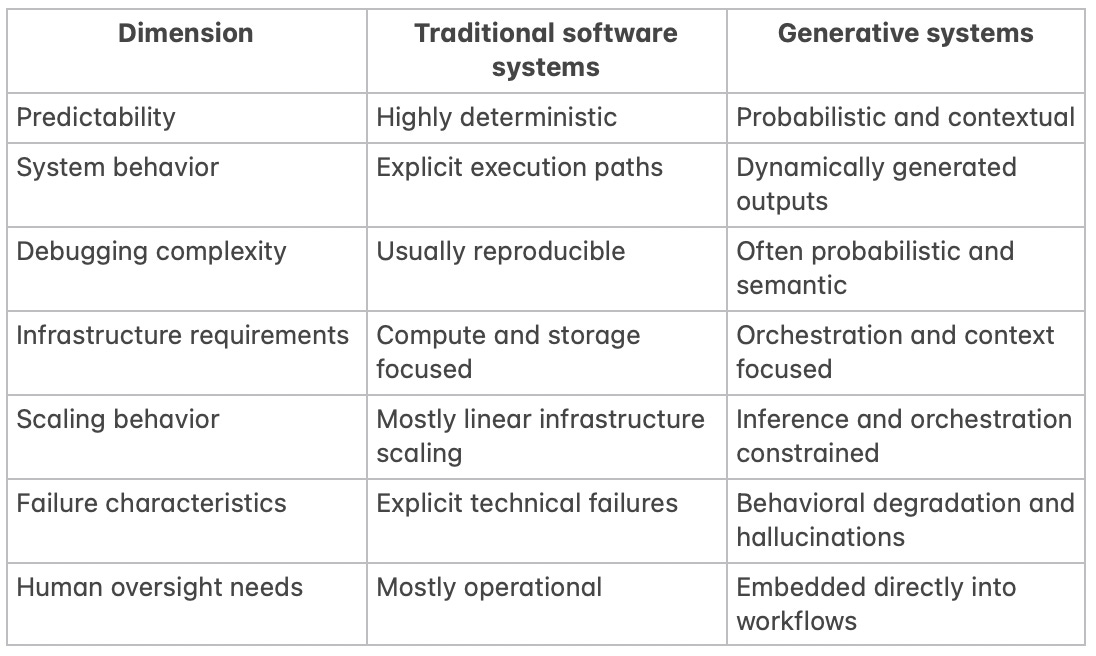
What this comparison reveals is that generative systems are not simply “traditional software plus AI.” They represent a deeper architectural transition toward systems whose behavior emerges dynamically rather than deterministically. Engineers increasingly design environments that shape probabilistic outcomes instead of controlling exact execution paths directly.
That requires a different mindset operationally. Reliability becomes probabilistic. Observability becomes semantic. Infrastructure becomes partially behavioral. Traditional software abstractions still matter enormously, but they no longer fully describe how these systems behave under real-world conditions.
Failure becomes harder to classify
Failure in generative systems is fundamentally more difficult to categorize than failure in traditional software. In deterministic systems, failures usually emerge from identifiable code paths, infrastructure outages, or implementation bugs. Generative systems often fail through interactions between components rather than explicit technical breakdowns.
Hallucinations emerge probabilistically. Retrieval pipelines surface misleading context. Memory systems influence future behavior unexpectedly. Reasoning quality degrades gradually across conversational state transitions. Context leakage introduces subtle inconsistencies that may not appear in infrastructure metrics at all.
In traditional systems, bugs usually come from code paths. In generative systems, failures increasingly emerge from interactions.
This changes debugging itself. Engineers increasingly investigate behavioral patterns rather than isolated implementation faults. Root causes may involve retrieval ranking, prompt structure, memory contamination, orchestration timing, token allocation, or contextual interactions across multiple systems simultaneously.
The architecture becomes harder to reason about because no single subsystem fully determines outputs independently anymore. Behavior emerges collectively across interacting probabilistic layers.
And collective behavior is always harder to constrain operationally.
The changing role of software engineers
As generative systems evolve, the role of software engineers shifts gradually alongside them. Engineers increasingly spend less time encoding explicit behavior directly and more time orchestrating environments where behavior emerges dynamically through models, retrieval systems, policies, memory layers, and evaluation pipelines.
The work becomes more about coordination than direct control.
Observability systems grow more important because engineers need visibility into semantic degradation and behavioral drift. Policy layers become architectural concerns rather than compliance afterthoughts. Evaluation infrastructure expands because testing probabilistic systems requires continuous behavioral assessment rather than static correctness verification alone.
Engineering in 2026 feels different partly because software itself behaves differently. Systems increasingly adapt, generate, retrieve, and reason rather than merely execute instructions deterministically. That changes how engineers think about ownership, reliability, debugging, and operational governance.
The architecture becomes less mechanical and more ecological.
Misconceptions about generative system design
Several misconceptions continue distorting discussions around generative systems. One is the belief that better models automatically solve infrastructure problems. In reality, stronger models often increase orchestration complexity, observability requirements, and operational cost simultaneously.
Another misconception is that generative systems are “just APIs with prompts.” Production systems increasingly involve sophisticated retrieval pipelines, memory architectures, policy enforcement layers, routing systems, evaluation infrastructure, and coordination frameworks far beyond isolated prompt interactions.
There is also a persistent belief that more autonomy automatically improves systems. Operational reality often suggests the opposite. Greater autonomy increases flexibility while simultaneously increasing unpredictability, governance complexity, and trust challenges.
And perhaps most importantly, many organizations still underestimate how much traditional systems engineering remains necessary. Generative systems do not replace architecture. They make architecture more important because probabilistic systems require stronger orchestration, observability, and coordination infrastructure around them.
What generative systems reveal about the future of software
Generative systems reveal something larger about where software itself is heading. Software is gradually shifting from deterministic execution environments toward adaptive systems capable of probabilistic reasoning, contextual behavior, and dynamic orchestration.
That shift changes engineering culture fundamentally. Reliability becomes less absolute. Ownership becomes more distributed across interacting systems. Observability expands beyond infrastructure health into behavioral monitoring. Human oversight becomes infrastructural rather than exceptional.
The future of software likely involves systems that remain partially unpredictable operationally even when functioning correctly. Engineers increasingly design architectures not around eliminating uncertainty entirely, but around constraining and managing uncertainty intelligently.
That is a very different philosophy from traditional software engineering.
And honestly, the industry still has not fully absorbed what that means yet.
Conclusion: architecture in a world of probabilistic systems
Generative systems represent a deeper architectural shift than most discussions currently acknowledge. They are not simply new interfaces layered on top of existing software patterns. They change foundational assumptions about predictability, orchestration, reliability, observability, and system behavior itself.
Engineers are increasingly designing systems whose outputs cannot be fully predicted ahead of time. The architecture revolves less around deterministic execution and more around shaping probabilistic behavior through orchestration, retrieval, context management, policy enforcement, and human oversight.
That does not make traditional software engineering obsolete. Distributed systems, scalability, infrastructure reliability, and operational discipline still matter enormously. But they now coexist with systems whose behavior emerges dynamically rather than mechanically.
The hardest part of generative systems isn’t making them intelligent. It’s building systems around intelligence that behaves unpredictably.