

Generative AI System Design and the infrastructure nobody shows on stage
The difficult part of generative AI isn’t getting a model to respond. It’s building a system that keeps responding reliably when reality becomes messy.

From the outside, most generative AI products look deceptively simple. A user types a question into a text box, waits a few seconds, and receives something that appears intelligent, conversational, and contextually aware. The interface resembles ordinary software. There is a prompt, a response, and the familiar illusion that the complexity underneath must be manageable because the interaction itself feels clean. This is partly why generative AI systems spread so quickly across the industry. The demos looked effortless. A few API calls, a polished interface, and suddenly software appeared capable of reasoning in natural language.
Production systems tell a very different story.
The operational reality of deploying large-scale generative AI systems is far messier than the demos imply. Once these systems leave controlled environments and encounter real users, infrastructure complexity expands rapidly. Latency becomes unpredictable. Costs fluctuate nonlinearly. Outputs drift semantically. Retrieval systems introduce inconsistency. Moderation pipelines become mandatory. Observability becomes partially behavioral instead of purely infrastructural. The engineering challenge stops being “getting the model to respond” and becomes something much larger: building reliable systems around probabilistic generation engines that do not behave deterministically.
The difficult part of generative AI isn’t getting a model to respond. It’s building a system that keeps responding reliably when reality becomes messy.
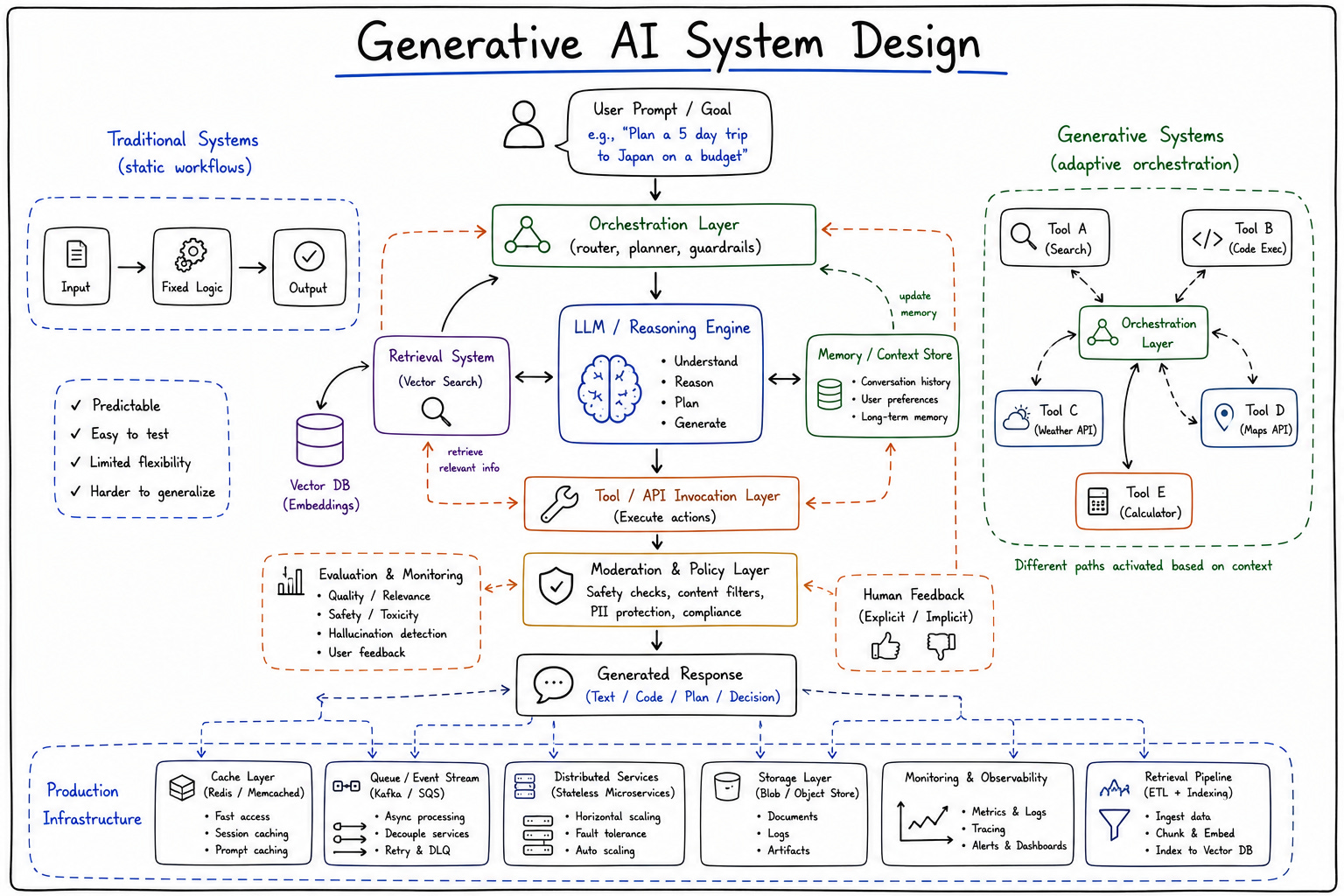
That distinction matters because generative AI system design is fundamentally an infrastructure problem as much as it is a modeling problem. The model itself is only one component inside a much larger operational ecosystem involving inference orchestration, retrieval infrastructure, memory systems, observability tooling, evaluation pipelines, moderation frameworks, and increasingly complicated coordination layers. And unlike traditional software systems, many of these components interact probabilistically rather than deterministically. The architecture behaves less like a machine executing instructions and more like an environment continuously shaping uncertain outcomes.
Inference becomes infrastructure
One of the biggest operational shifts introduced by generative AI is that inference itself became a primary architectural concern. In traditional software systems, computation was usually relatively cheap compared to storage, networking, or coordination complexity. In generative AI systems, inference becomes one of the dominant operational bottlenecks almost immediately.
Serving large models at scale introduces infrastructure challenges most traditional SaaS architectures never encounter directly. GPU allocation becomes operationally critical. Batching strategies influence latency behavior. Model routing decisions shape cost structures. Throughput constraints become tied directly to hardware availability and inference scheduling efficiency.
Larger models increase latency
Better reasoning increases cost
Lower latency often reduces quality
This creates difficult trade-offs operationally. Organizations want higher-quality outputs, but larger reasoning models increase inference cost and latency significantly. Users expect conversational responsiveness, but maintaining low latency often requires routing requests toward smaller or simplified models that may reduce output quality. Infrastructure decisions become tightly coupled with product behavior because inference economics directly shape architectural constraints.
What makes this particularly unusual is that scaling generative systems differs fundamentally from scaling ordinary software systems. In traditional SaaS environments, additional users often scale relatively efficiently through horizontal infrastructure expansion. Generative AI systems scale expensively because each additional interaction may require significant incremental compute. The infrastructure cost scales with usage intensity much more directly.
And unlike ordinary APIs, inference workloads fluctuate semantically rather than uniformly. Longer prompts, deeper reasoning chains, retrieval augmentation, and multi-step orchestration all increase computational demand unpredictably.
Retrieval pipelines quietly became part of the architecture
One of the more important operational realizations in production generative AI systems is that models alone are rarely sufficient. Static model knowledge degrades quickly operationally because production systems require current, contextual, organization-specific, or dynamically changing information that pretrained models cannot reliably encode internally.
This is why retrieval-augmented generation systems became foundational so quickly.
Modern generative systems increasingly depend on external retrieval infrastructure involving embeddings, vector databases, semantic search pipelines, ranking systems, and dynamic context injection. The architecture no longer revolves around the model alone. It revolves around continuously assembling knowledge dynamically from external information environments.
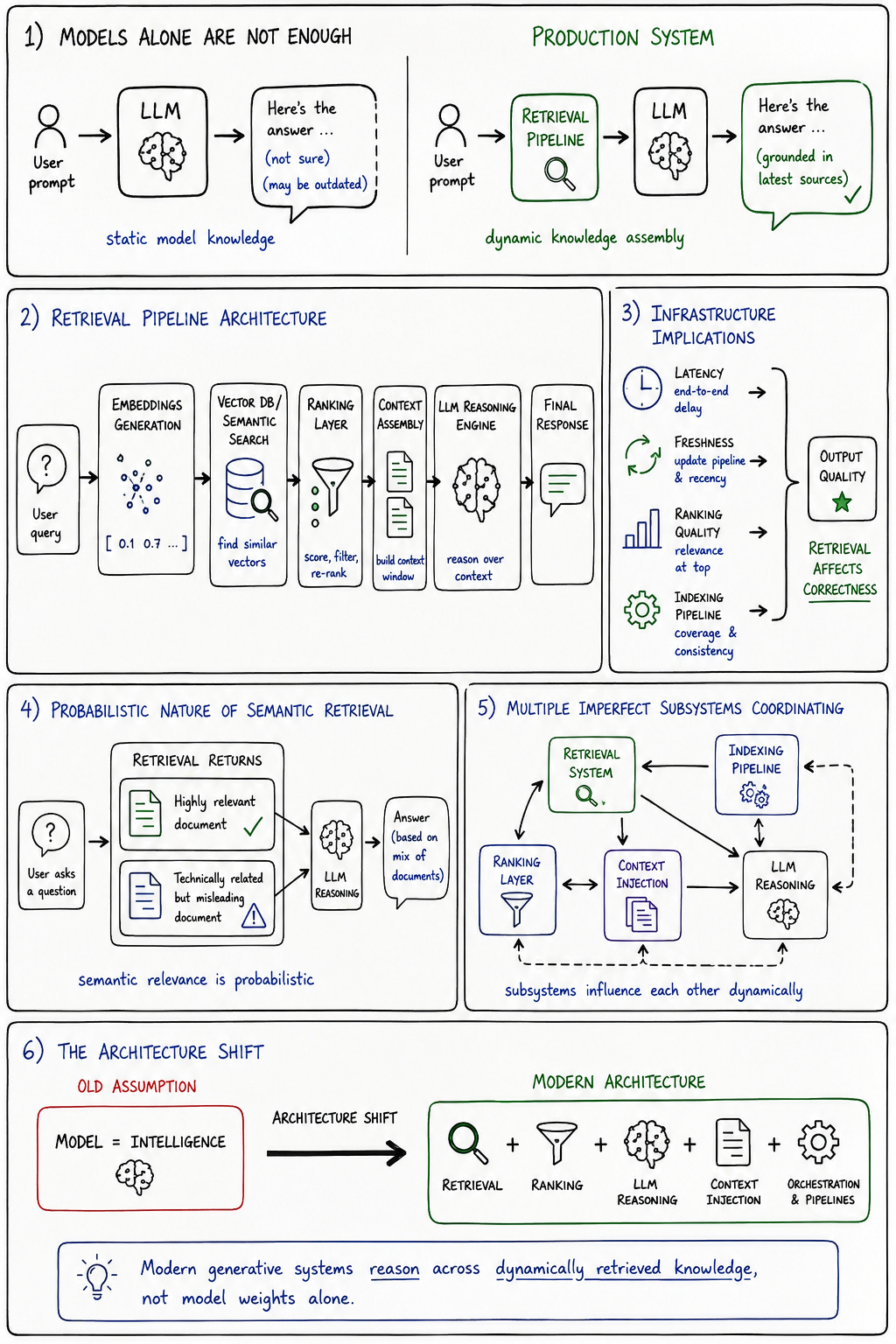
That shift changes infrastructure assumptions significantly. Retrieval latency becomes part of user experience quality. Embedding freshness becomes operationally meaningful. Ranking quality directly influences hallucination behavior. Knowledge indexing pipelines become reliability infrastructure rather than optional enhancements.
The interesting thing about retrieval systems is that they introduce probabilistic complexity of their own. Retrieval does not merely fetch “correct” information deterministically. It surfaces semantically relevant information probabilistically based on embedding similarity, ranking heuristics, indexing strategies, and contextual interpretation. The retrieved information may be technically related while still operationally misleading.
This creates systems where correctness increasingly depends on interactions between retrieval pipelines and model reasoning behavior rather than either component independently. The architecture becomes a coordination system managing probabilistic interactions between multiple imperfect subsystems.
Context management becomes operationally critical
Context management has quietly become one of the defining infrastructure challenges in production generative AI systems. Traditional software systems generally treat context as application state. Generative systems treat context as part of the execution environment itself.
Context windows shape model reasoning behavior directly. Token limits constrain what information remains available during inference. Memory systems alter outputs over time. Retrieval pipelines dynamically reshape conversational state. The architecture increasingly revolves around managing which information the model sees, how it is structured, and when it becomes available operationally.
In generative AI systems, context is no longer just data. It becomes part of the execution environment itself.
This creates unusual infrastructure concerns. Longer context windows improve coherence but increase latency and inference cost. Memory persistence improves continuity while simultaneously increasing unpredictability. Context assembly pipelines influence reasoning quality as much as model capability itself. Engineers spend enormous amounts of time optimizing how context is retrieved, compressed, ranked, filtered, and injected because context management directly affects output behavior.
What makes this operationally difficult is that context behaves probabilistically rather than deterministically. Small contextual shifts can produce disproportionately different outputs. Retrieval ordering matters. Token truncation matters. Historical conversation state matters. The system becomes highly sensitive to contextual structure in ways traditional software systems generally are not.
This is partly why many early AI demos failed operationally at scale. The demos assumed static context conditions. Production environments continuously distort context dynamically through user behavior, retrieval inconsistency, conversational drift, and orchestration complexity.
Hallucinations are infrastructure problems too
Hallucinations are often framed as purely model-quality failures, but production environments reveal something more complicated. AI model hallucination frequently emerges from infrastructure interactions rather than isolated model defects alone.
Retrieval quality affects hallucination frequency significantly. Context fragmentation introduces reasoning inconsistencies. Prompt assembly pipelines distort semantic interpretation. Orchestration systems may inject incomplete or conflicting contextual information. Memory contamination gradually alters future outputs. Hallucinations often emerge from probabilistic interactions across the architecture rather than solely from the model itself.
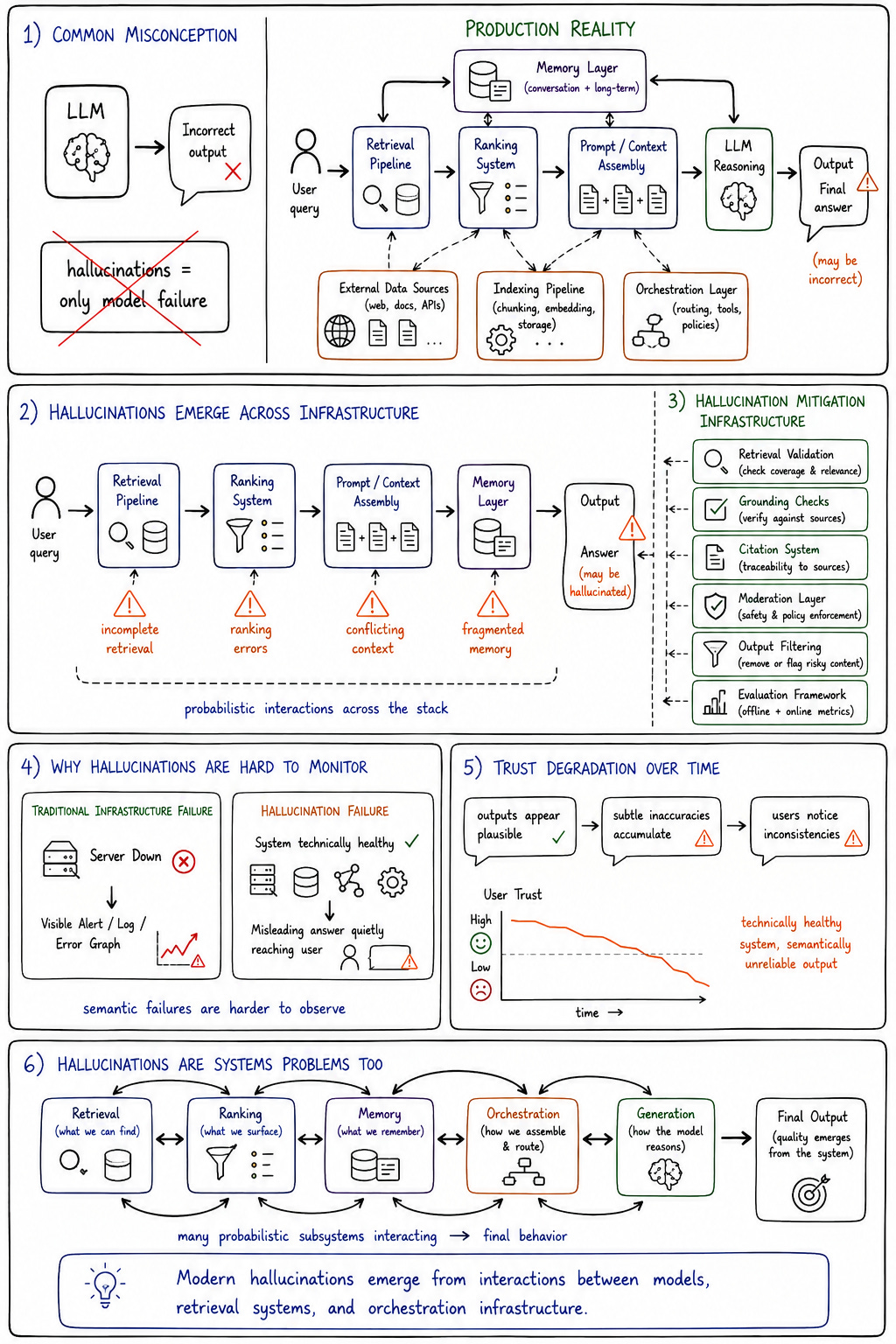
This is one reason hallucination mitigation increasingly becomes a systems engineering problem. Organizations implement retrieval validation, citation pipelines, semantic ranking systems, grounding checks, moderation layers, output filtering, and evaluation frameworks not because the models are “broken,” but because probabilistic generation operating across imperfect infrastructure introduces unavoidable uncertainty.
The deeper challenge is that hallucinations are difficult to monitor operationally. Traditional infrastructure failures are measurable directly through metrics and logs. Hallucinations require semantic interpretation. A system may remain technically healthy while producing subtly misleading outputs that degrade trust gradually over time.
This creates a category of operational failure that traditional observability systems were never designed to capture fully.
Orchestration becomes more important than the model itself
One of the more surprising developments in production generative AI systems is that orchestration layers increasingly dominate operational complexity. The model itself often becomes only one component inside a much larger coordination architecture.
Production systems coordinate multiple models, retrieval pipelines, policy engines, moderation systems, external APIs, evaluation frameworks, memory layers, routing logic, and observability tooling simultaneously. Requests flow through adaptive orchestration pipelines rather than static application workflows. Different models may handle reasoning, summarization, ranking, or moderation separately depending on context and operational constraints.
This changes how engineers think about system design entirely. The architecture stops behaving like a deterministic request pipeline and starts behaving like an adaptive orchestration environment coordinating probabilistic subsystems dynamically.
The orchestration layer becomes responsible for managing uncertainty operationally. It decides which retrieval systems to invoke, how much context to inject, which models to route toward, when to trigger fallback behavior, and how to constrain outputs through policy enforcement systems.
Ironically, many modern AI products are operationally more orchestration systems than AI systems. The model may receive most of the public attention, but the surrounding coordination infrastructure often determines whether the product behaves reliably in practice.
Observability changes in generative AI systems
Traditional observability systems were designed around deterministic infrastructure assumptions. CPU utilization, latency distributions, error rates, throughput metrics, and service availability generally correlate reasonably well with system health.
Generative AI systems complicate that relationship significantly.
Infrastructure may appear healthy while outputs degrade semantically. Latency metrics do not capture reasoning quality. Hallucinations rarely appear directly in dashboards. Behavioral drift may accumulate gradually without triggering obvious operational alarms.
Infrastructure may appear healthy while outputs degrade
Latency metrics don’t capture reasoning quality
Semantic failures rarely show up in dashboards directly
This forces organizations to build new forms of observability focused partially on behavior rather than purely infrastructure state. Evaluation systems increasingly monitor semantic correctness, retrieval quality, policy compliance, conversational coherence, and hallucination rates continuously. Human review pipelines often remain embedded operationally because fully automated quality assessment remains difficult.
Observability becomes interpretive rather than purely mechanical. Engineers increasingly investigate why systems behaved a certain way semantically rather than simply whether services remained available technically.
That represents a substantial shift in operational engineering philosophy.
Traditional distributed systems vs generative AI systems
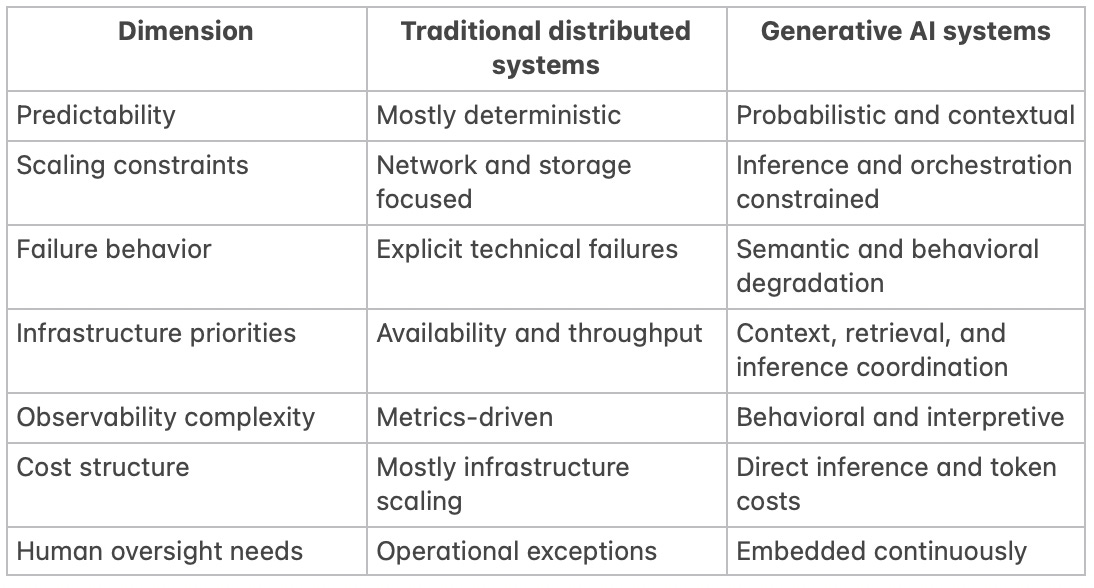
The comparison highlights why generative AI infrastructure requires a different operational mindset. Traditional distributed systems optimize around deterministic coordination. Generative systems optimize around managing uncertainty probabilistically across interacting subsystems.
This does not eliminate traditional infrastructure concerns. Scalability, reliability, networking, storage, and coordination still matter enormously. But they now coexist with probabilistic generation layers whose behavior cannot be fully predicted operationally.
That combination creates infrastructure environments fundamentally different from traditional software systems.
Why scaling GenAI systems becomes economically difficult
Scaling generative AI systems introduces economic constraints that behave differently from traditional SaaS infrastructure. Inference cost scales directly with usage intensity. Token consumption grows nonlinearly across orchestration layers. Retrieval complexity increases latency overhead. Evaluation systems consume additional infrastructure resources continuously.
GPU utilization becomes a dominant operational concern because inefficient inference scheduling can destroy unit economics rapidly. Retrieval pipelines introduce additional infrastructure coordination overhead. Context expansion increases both latency and token cost simultaneously. Better reasoning often requires larger models or multi-step orchestration, which further increases operational expense.
The easiest generative AI system to scale is the one nobody actually uses in production.
Traditional SaaS systems benefit heavily from economies of scale once infrastructure stabilizes. Generative systems often experience the opposite dynamic because each additional user interaction may introduce substantial incremental compute demand. This forces organizations to think much more aggressively about routing efficiency, model specialization, caching behavior, retrieval optimization, and orchestration discipline.
The architecture becomes economically constrained in ways ordinary web applications rarely are.
Human oversight quietly returned to the center
One of the more interesting consequences of generative AI infrastructure is that fully autonomous systems remain operationally uncomfortable in most real-world environments.
Organizations increasingly layer moderation systems, approval workflows, policy enforcement engines, review pipelines, and human validation mechanisms directly into generative architectures because probabilistic systems create uncertainty that many operational environments cannot tolerate fully unattended.
Generative AI systems automate output generation, but they also create entirely new categories of uncertainty that organizations still need humans to manage.
This is a significant reversal from earlier automation narratives. AI systems frequently increase the importance of human oversight rather than eliminating it entirely. Humans increasingly supervise outputs, validate reasoning quality, manage edge cases, monitor behavioral drift, and intervene during uncertainty escalation scenarios.
Operational trust becomes infrastructural rather than purely organizational. Engineers now design systems assuming that humans remain part of the architecture itself.
Misconceptions about generative AI system design
Several misconceptions continue distorting conversations around production generative AI infrastructure.
“The model is the system.”
It is not. The model is one component inside a much larger orchestration environment involving retrieval, context management, policy enforcement, observability, and evaluation systems.
“Better models solve operational problems.”
Stronger models often increase orchestration complexity, inference cost, and observability requirements simultaneously.
“RAG fixes hallucinations completely.”
Retrieval reduces some hallucination patterns while introducing retrieval quality, ranking, and context consistency challenges of its own.
“Scaling GenAI systems is mostly about compute.”
Compute matters enormously, but orchestration efficiency, retrieval coordination, observability, and cost management increasingly dominate operational complexity.
“Prompt engineering replaces architecture.”
Prompting influences behavior. It does not eliminate the need for reliable infrastructure, retrieval systems, evaluation pipelines, or operational governance.
These misconceptions persist partly because demos still hide most of the difficult infrastructure work underneath polished interfaces.
What generative AI infrastructure reveals about software engineering
Generative AI systems blur boundaries between software engineering, ML infrastructure, information retrieval, distributed systems, and orchestration engineering. The architecture increasingly spans domains that historically operated relatively independently.
Engineers now reason simultaneously about inference behavior, retrieval quality, orchestration coordination, observability systems, policy enforcement, memory management, and infrastructure economics. The role itself becomes more interdisciplinary because the systems themselves operate across multiple interacting layers of uncertainty.
This changes engineering culture gradually. Observability becomes partially behavioral. Reliability becomes probabilistic. Coordination becomes more important than isolated implementation details. Engineers spend more time shaping system behavior through orchestration than directly controlling execution paths deterministically.
The architecture becomes less mechanical and more ecological.
The future of generative AI architecture
The next phase of generative AI infrastructure will likely involve increasingly sophisticated orchestration systems coordinating multiple specialized models dynamically. Adaptive routing layers will optimize between cost, latency, and reasoning quality continuously. Retrieval-centric architectures will become more important as organizations rely increasingly on external knowledge systems rather than static model knowledge alone.
AI-native observability systems will mature because traditional infrastructure monitoring remains insufficient for probabilistic behavior. Policy-driven orchestration frameworks will expand as organizations seek stronger governance around autonomous generation systems.
But the systems that succeed operationally are unlikely to be the ones pursuing unrestricted autonomy aggressively. More likely, successful architectures will emphasize carefully constrained probabilistic behavior operating inside robust orchestration and observability environments.
The future probably belongs to systems that manage uncertainty intelligently rather than pretending uncertainty disappears entirely.
Final words: systems built around probabilistic intelligence
Generative AI system design is fundamentally about building reliable infrastructure around unreliable generation. The challenge is not simply model capability. It is orchestration, retrieval, observability, context management, inference coordination, evaluation infrastructure, and operational discipline layered around probabilistic systems that do not behave deterministically.
Traditional software engineering assumptions still matter enormously. Distributed systems, scalability, infrastructure reliability, and operational rigor remain foundational. But they now coexist with systems whose behavior emerges dynamically from probabilistic interactions across models, retrieval pipelines, memory systems, and orchestration layers.
That changes how engineers think about architecture itself.
The hardest problem in generative AI system design isn’t making systems intelligent. It’s making probabilistic systems operationally trustworthy.